시작하기 전에
본 자료는 빠른 속도와 메모리 효율성에 강점이 있는 data.table 패키지에 관해 기본 개념과 문법, 함수들을 예제를 통해 다루어 볼 것이다.
1. 개념 소개
data.table 패키지는 대용량의 데이터를 분산 처리 시스템 없이 처리할 수 있는 방법으로, 데이터 프레임을 대신하여 더 빠르고 편리하게 사용할 수 있는 데이터 타입이다.
장점- 상대적으로 메모리 요구량이 적고, 속도가 매우 빠르다.
단점- 다소 난해한 문법으로 널리 사용되지는 못하고 있다.
2. 기본 문법
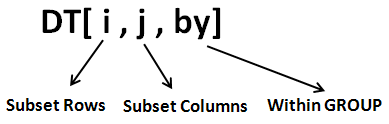
data.table 의 기본 문법은 DT[i, j, by] 형태이다.
- i는 행을 선택힌다.
- j는 열을 선택하거나 열 또는 테이블 전체에 함수를 적용한다.
- by는 집단을 나눈다. j에서 지정한 열과 함수를 by 그룹 별로 수행한다.
- 뒤에 [order]를 붙여 오름차순이나 내림차순으로 정렬할 수 있다.
Load & save data: fread & fwrite
fread 함수로 빠르게 csv 파일을 읽어와서 data.table 자료로 만들 수 있고, fwrite 함수로 csv 파일을 쓸 수 있다. fread와 fwrite 는 이름답게 매우 빠르며 Base R의 함수보다 40배 더 빠른 속도를 자랑한다. 파일을 읽어와서 data.table 자료로 만들 때, 로컬 file path를 입력하거나 http:// 로 시작하는 url을 입력하는 방법을 사용한다. fread로 파일을 읽으면 그 class는 data.frame에 data.table이 추가되며 문법이 원래의 data.frame과 달라지는 점을 유의하자.
fread를 통해 데이터를 불러와 data.table 형태로 만들어보자. 데이터는 09-15년 공단 건강검진 데이터에서 실습용으로 32명을 뽑은 자료이며, 자세한 내용은 “data/2교시 테이블 세부 레이아웃 소개(최신자료).pdf” 를 참고하자.
Setup
## Setup
# install.packages("data.table")
# install.packages("curl")
library(data.table)
library(curl)Using libcurl 8.6.0 with LibreSSL/3.3.6Load file
# Load file
url <- "https://raw.githubusercontent.com/jinseob2kim/lecture-snuhlab/master/data/example_g1e.csv"
df <- read.table(url,header=T)
dt <- fread(url,header=T)
# Class
print(class(df))[1] "data.frame"[1] "data.table" "data.frame"dt의 class에 data.table이 추가된 것을 볼 수 있다.
# dt = data.table(df)
# df = data.frame(dt)
## See
dtSave file
# Save file
write.csv(dt, "aa.csv",row.names=F)
fwrite(dt, "aa.csv")row operation
행을 선택하는 slice는 data.table에서 DT[c(row1, row2, …),] 또는 DT[c(row1, row2, …)]의 형식으로 data.frame과 동일하게 쓰인다.
dt[c(3,5)]특정한 조건을 만족하는 행을 선택하는 filter는 data.table에서 DT[cond]의 형식으로 쓰인다.
(이때, cond는 논리형 벡터이다.)
dt[BMI>=30 & HGHT<150]미리 key들을 지정하면 더 빠르게 검색할 수 있다. 자세한 내용은 뒤에서 다루도록 하겠다.
column operation
열을 이름 또는 순번으로 선택하는 select는 DT[, .(cols)] 또는 DT[, list(cols)]의 형식으로 data.frame과 비슷하나 몇 가지 차이점이 있다. 변수 이름으로 선택하는 경우 앞에 .()이나 list를 붙이지 않으면 결과로 벡터가 반환된다.
- 순번으로 열 선택
dt[, c(13, 14)]- 이름으로 열 선택
## same
# dt[, list(HGHT, WGHT)]
dt[, .(HGHT, WGHT)]열을 선택할 때 DT[, .(new_col = col)] 형식을 사용하여 열 이름을 지정해서 출력할 수 있다.
# rename
dt[, .(Height = HGHT, Weight = WGHT)]- 변수로 열 선택
## same
# vars <- c(13,14)
vars <- c("HGHT", "WGHT")
dt[, ..vars]변수로 열을 선택하는 경우, 변수 앞에 ..을 붙이지 않으면 오류가 발생하므로 주의하도록 한다. .. 대신 with = F 를 뒤에 붙이거나 .SD, .SDcols 옵션을 사용하기도 한다. .SD는 뒤에서 더 자세히 다루도록 하겠다.
dt[, vars, with = F]- 열 제외
필요없는 열을 제외할 때는 - 또는 ! 를 붙인다.
icols = c(1:12)
## same
# dt[, -..icols]
dt[, !..icols]data.table의 column operation에서는 열을 선택할뿐만 아니라 연산하는 식을 처리할 수 있다. 앞에서 배운 내용을 통해 특정 조건을 만족하는 행을 대상으로 mean 연산을 수행하여 보자.
by operation
by 옵션을 이용하여 그룹별로 함수를 적용할 수 있다. by=.(그룹1, 그룹2, …)을 사용해 두 개 이상의 그룹별로 함수를 적용할 수 있다. 이때 괄호 앞에 있는 점(‘.’)은 list()를 의미하므로 꼭 포함시키도록 한다. by 대신 keyby를 사용할 경우, 그룹별 집계 결과가 정렬되어 나타난다.
연도 변수인 EXMD_BZ_YYYY을 기준으로 집단을 분리한 후 각 집단의 HGHT와 WGHT, BMI 평균을 구하는 방법은 다음과 같다.
기준으로 사용되지 않은 모든 열에 대해 평균을 구할때는 .SD를 사용한다. 이는 뒤에서 더 자세히 다루도록 하겠다.
dt[, lapply(.SD, mean), by=EXMD_BZ_YYYY]이번에는 두 개의 그룹 변수를 지정해 행의 개수를 출력해보자.
dt[HGHT >= 175, .N, by=.(EXMD_BZ_YYYY, Q_SMK_YN)]정렬
그룹별로 함수를 적용한 결과를 정렬하고자 할 때는 keyby를 사용하거나 마지막에 [order()]를 붙인다.
- keyby
dt[HGHT >= 175, .N, keyby=.(EXMD_BZ_YYYY, Q_SMK_YN)]by를 사용한 예제와는 달리 Q_SMK_YN에 대해서 정렬된 것을 볼 수 있다.
- [order()]
Expressions in by
by 옵션에는 변수뿐만 아니라 식을 지정할 수도 있다.
약물 치료 여부에 따른 환자수를 확인하려는 경우, 다음과 같이 식을 지정한다.
dt[, .N, by=.(Q_PHX_DX_STK > 0, Q_PHX_DX_HTDZ > 0)]3. functions
- key를 이용한 탐색 setkey()
- 데이터 테이블 병합 merge()
- 데이터 테이블 수정 연산자 :=
- 특수 기호 .SD , .SDcols, .N
key를 이용한 탐색 setkey()
key를 사용하면 데이터의 탐색 및 처리 속도가 매우 향상된다. setkey(DT, col)로 키를 설정하며 키가 문자열 벡터일 경우 setkeyv을 활용한다. 설정되어 있는 키를 제거할 때는 setkey(DT, NULL)를 설정한다.
- 키 설정
setkey를 활용해 데이터 테이블에 키를 설정하고, key 함수로 설정된 키를 확인할 수 있다.
# 1 key
setkey(dt, EXMD_BZ_YYYY)
key(dt)[1] "EXMD_BZ_YYYY"# 2 keys
setkey(dt, EXMD_BZ_YYYY, Q_HBV_AG)
key(dt)[1] "EXMD_BZ_YYYY" "Q_HBV_AG" - 키를 활용한 행 선택
dt[.(a)], dt[J(a)], dt[list(a)], dt[col == a] 중에서 아무거나 사용하여 행을 선택할 수 있다.
## same
# dt[.(2011)]
# dt[list(2011)]
# dt[EXMD_BZ_YYYY==2011]
dt[J(2011)]## same
# dt[.(2011, 2)]
# dt[list(2011, 2)]
# dt[EXMD_BZ_YYYY==2011 & Q_HBV_AG==2]
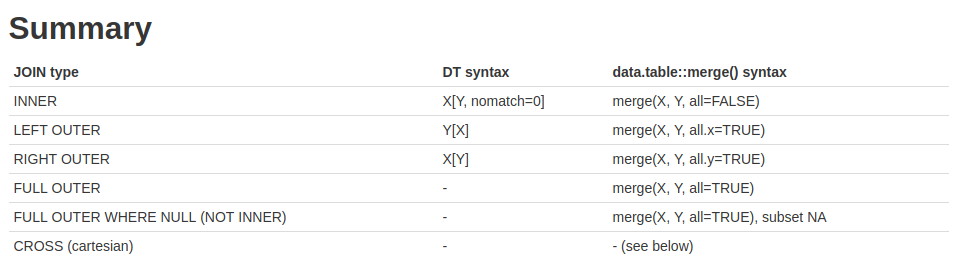
dt[J(2011, 2)]데이터 테이블 병합 merge()
data.table은 key를 사용하거나, on=을 활용하여 두 데이터 데이블을 병합할 수 있다.
기존 데이터를 가공하여 새로운 data.table인 dt1, dt2에 저장하고 연도에 따라 merge해 보자.
# dt1
(dt1 <- dt[c(1, 300, 500, 700, 1000)])
setkey(dt1, EXMD_BZ_YYYY)# dt2
(dt2 <- dt[c(400, 600, 800 ,1200, 1500)])
setkey(dt2, EXMD_BZ_YYYY)1. inner join
두 데이터에 모두 존재하는 경우 dt1[dt2, on=‘key’, nomatch=0] 또는 merge(dt1, dt2, by=‘key’, all=F) 형식 사용
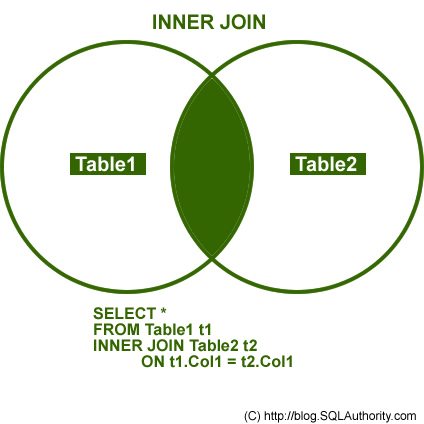
dt1[dt2, on='EXMD_BZ_YYYY', nomatch=0]# same
merge(dt1, dt2, by='EXMD_BZ_YYYY', all = F)2. left_outer_join
첫 번째 데이터에 존재하는 경우 dt2[dt1, on=‘key’] 또는 merge(dt1, dt2, by=‘key’, all.x=T) 형식 사용
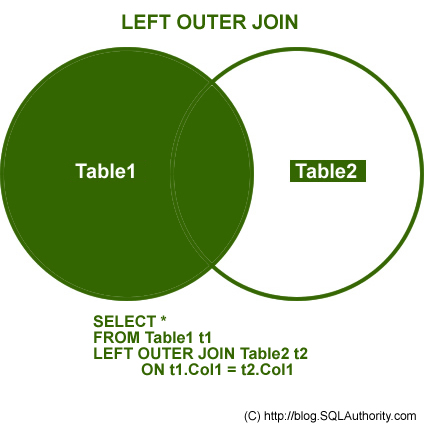
dt2[dt1, on='EXMD_BZ_YYYY']# same
merge(dt1, dt2, by='EXMD_BZ_YYYY', all.x=T)3. right_outer_join
두 번째 데이터에 존재하는 경우 dt1[dt2, on=‘key’] 또는 merge(dt1, dt2, by=‘key’, all.y=T)형식 사용
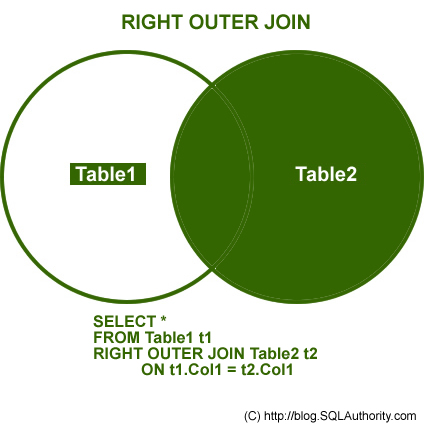
dt1[dt2, on='EXMD_BZ_YYYY']# same
merge(dt1, dt2, by='EXMD_BZ_YYYY', all.y=T)4. full_outer_join
어느 한 쪽에 존재하는 경우 merge(dt1, dt2, by=‘key’, all=T) 형식 사용
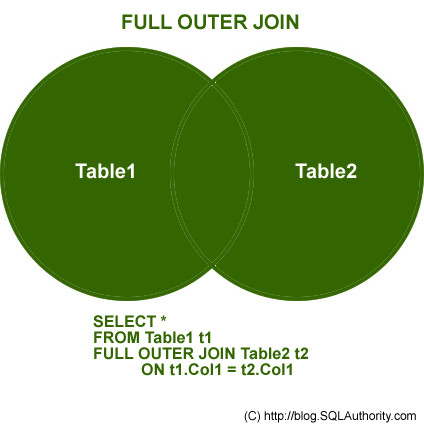
merge(dt1, dt2, by='EXMD_BZ_YYYY', all=TRUE)데이터 테이블 수정 연산자 :=
데이터 테이블에서 열 j를 추가하거나 갱신 또는 삭제할 때 특수 기호 := 연산자를 사용한다. 수정 또는 생성할 열이 하나인 경우, dt[ , newcol1 := ] 형식을 쓰며 열이 두 개 이상인 경우 dt[, ‘:=’ (col1=, col2=)]을 사용한다.
다음의 예시를 통해서 자세히 알아보자.
기존의 데이터 테이블에서 HDL - LDL을 구해서 diff라는 이름의 열을 새로 생성한다. 그리고, HGHT와 WGHT는 HGHT*0.9, WGHT+5로 수정한다.
열 생성/수정
위 코드를 실행시키면 갱신이 눈에 보이지 않는 상태로 실행되며, 만약 갱신 결과를 눈에 보이도록 출력하려면 제일 뒤에 [] 를 붙여주어야 한다.
# 열 생성
dt[, diff := HDL-LDL][]# 열 수정
dt[, ':=' (HGHT = HGHT*0.9, WGHT = WGHT+5)][]열 삭제
데이터 테이블에서 열을 삭제하려면 col := NULL 형식을 사용한다.
# BMI 삭제
dt[, BMI := NULL]특수 기호
.SD
.SD 는 ’Subset of Data’의 약자로, by로 지정한 그룹 칼럼을 제외한 모든 칼럼을 대상으로 연산을 수행할 때 사용한다.
# 모든 칼럼의 연도별 평균값
dt[, lapply(.SD, mean), by=EXMD_BZ_YYYY]
또한 .SD 기호를 사용하여 연도별로 처음 두 개의 행을 추출할 수 있다.
dt[, head(.SD, 2), by=EXMD_BZ_YYYY].SDcols
.SDcols는 연산 대상이 되는 특정 칼럼을 지정하는 특수 기호이다. 특정 열을 대상으로 연산을 할 때 by 다음에 .SDcols = c(“col1”, “col2”, …)로 연산 대상을 지정한다.
.N
.N는 부분 데이터의 행의 수를 나타내며, 요약 통계치를 구할 때 대상 데이터의 수를 간편하게 구할 수 있다.
# 특정 조건을 만족하는 행의 수
dt[LDL >= 150, .N][1] 2284. 데이터 재구조화 melt & dcast
마지막으로 효율적으로 data의 형태를 바꾸는 melt(wide to long)와 dcast(long to wide) 를 알아보겠다. melt 함수는 데이터 테이블을 녹여서 넓은 자료구조를 길게 재구조화하며, dcast 함수는 데이터 테이블을 주조하여 긴 자료구조를 넓게 재구조화한다.
melt
melt 함수는 일부 고정 칼럼을 제외한 나머지 칼럼을 stack 처리할 수 있다. melt(data, id.vars, measure.vars, variable.name, value.name) 형식으로 쓰이며, id.vars에는 고정 칼럼을 measure.vars는 stack 처리할 칼럼을 넣는다. melt함수를 써서 길게 재구조화한 후의 “variable”, “value” 변수 이름을 바꾸고 싶다면 variable.name=“new_var_name”, value.name=“new_val_name” 처럼 새로운 칼럼 이름을 부여하여 지정할 수 있다.
Enhanced melt
melt 함수는 동시에 여러 개의 칼럼들을 묶어서 사용할 수도 있다.
- list에 복수의 칼럼 이름을 입력하는 방법
melt 함수에 measure=list(col1, col2, …) 형식으로 여러 개의 칼럼 이름을 list() 형태로 넣는다. 이때 공통의 value.name을 지정할 수 있다.
- 특정 패턴을 정규 표현식으로 매칭하는 방법
melt 함수에 measure=patterns() 형식으로 특정 패턴을 따르는 복수의 칼럼을 정규 표현식을 통해 설정한다.
dt.long3 <- melt(dt,
measure=patterns("^Q_PHX_DX", "^BP"),
value.name=c("Q_PHX_DX", "BP"))
dt.long3dcast
dcast 함수는 melt 함수를 통해 길게 쌓여진 칼럼을 각 항목별로 분리하기 위해 사용한다. dcast(data, formula, value.var, fun.aggregate) 형식으로 쓰이며, formula의 LHS에는 id.vars, RHS에는 variable을 입력하고 value.name에는 “value”를 입력한다. 이때 “variable”과 “value” 변수 이름을 바꿨다면, 새로 지정한 칼럼명을 넣는다.
# long to wide
dt.wide1 <- dcast(dt.long1, EXMD_BZ_YYYY + RN_INDI + HGHT + WGHT ~ measure, value.var = "val")
dt.wide1dcast 함수에 집계 함수(fun.aggregate)를 사용하여 그룹별 요약 통계량을 계산한 결과를 재구조화하여 반환할 수 있다.
# 연도별 TOT_CHOL, HDL, LDL의 평균값
dt.wide2 <- dcast(dt.long1, EXMD_BZ_YYYY ~ measure, value.var = "val", fun.aggregate = mean, na.rm =T)
dt.wide2Enhanced dcast
dcast 함수의 value.vars에 복수의 칼럼을 넣어 여러 개의 칼럼을 동시에 재구조화할 수 있다.
dt.wide3 <- dcast(dt.long2,
... ~ variable,
value.var = c("BP", "Chol"))
dt.wide3마치며
-
data.table패키지를 사용하여 쉽고 빠르게 데이터를 가공할 수 있다. -
data.table의 기본 문법은 DT[i, j, by] 형태이며 그 쓰임새는 다음과 같다.- i : 행을 선택
- j : 열을 선택, 일정한 함수 적용
- by : 집단을 구성, j에서 지정한 열과 함수를 by 그룹 별로 수행
- key를 사용하여 데이터를 빠르게 탐색 및 처리할 수 있다.
- 열을 추가하거나 갱신 또는 삭제할 때 := 연산자를 사용한다.
-
data.table에는 여러 특수 기호가 존재한다.- .SD : 그룹 칼럼을 제외한 모든 칼럼을 대상으로 연산
- .SDcols : 연산 대상이 되는 특정 칼럼을 지정
- .N : 부분 데이터의 행의 개수
-
melt와dcast함수를 사용하여 데이터를 재구조화할 수 있다.
cheatsheet
Citation
BibTeX citation:
@online{lee2022,
author = {Lee, Yujin},
title = {Data.table {패키지} {소개}},
date = {2022-02-11},
url = {https://blog.zarathu.com/posts/2022-02-11-datatable/},
langid = {en}
}
For attribution, please cite this work as:
Lee, Yujin. 2022. “Data.table 패키지 소개.” February 11. https://blog.zarathu.com/posts/2022-02-11-datatable/.