김진섭 대표는 11월 28일(수) 중앙보훈병원 정신건강의학과를 방문, 의학 연구에 필요한 기술 통계(descriptive statistics)에 대해 강의하고 자체 제작한 웹 애플리케이션과 Rstudio Addins를 이용하여 실습을 진행하였습니다. 강의 내용을 공유합니다.
시작하기 전에
의학연구에서 R 활용 능력을 대략 5단계로 구분할 수 있다.
데이터 정리는 미리 excel로 완료, 통계분석만 R 이용.
R로 데이터 정리와 통계분석을 모두 수행.
R로 그림을 그린다.
논문에 들어갈 Table과 figure를 모두 R로 만든다.
글쓰기, 참고문헌 등 논문의 모든 작업을 R에서 직접 수행한다.
본 강의는 1단계에 해당하는 연구자가 R을 쉽게 이용할 수 있도록 돕는 내용에 해당하며 R과 Rstudio의 설치과정은 생략한다. 혹시 설치를 못했다면 https://www.r-project.org 와 https://www.rstudio.com/products/rstudio/download 를 참조하여 설치하길 바란다. R의 전반적인 도움말은 help.start() 명령어를 활용하고 특정 함수를 보려면 help(which) 형태로 실행하면 된다.
의학 연구에서의 기술 통계
기술 통계는 원래 평균(mean), 중위수(median), 분산(variance), 빈도표(frequency table)등의 데이터를 설명하는 숫자들이나 히스토그램(histogram), 상자그림(box-plot)같은 그래프를 의미한다. 그러나 대부분의 의학 연구에서는 단순한 기술 통계가 아닌 그것들의 그룹 비교(ex: 성별, 질환 유무)가 Table 1에 기술 통계란 제목으로 제시된다.
보통 연구의 흐름은 기술 통계로 데이터를 보여주고 단변량(univariate) 분석을 통해 가설 검정을 수행한 후, 다변량(multivariate) 혹은 소그룹(subgroup) 분석 을 이용하여 다른 변수들의 효과를 보정한 결과를 보여주는 것으로 이루어진다. 그러나 단변량 분석에서 끝나는 간단한 연구도 많고 이것은 본질적으로 기술 통계의 그룹 비교와 같으므로, Table 1에 필요한 통계를 알고 쉽게 구현할 수 있다면 그것만으로 간단한 의학 연구를 수행할 수 있다.
본 강의에서는 Table 1의 그룹 비교에 필요한 통계 방법들을 알아보고 R을 이용해서 실제 분석을 수행할 것이다. 통계 방법을 선택하는 기준은 크게 (1) 연속 변수(continuous variable) vs 범주형 변수(categorical variable), (2) 비교할 그룹 수, (3) 샘플 수 혹은 정규분포 여부 의 3가지가 있으며 추가로 짝지은 그룹인 경우를 살펴보겠다.
마지막으로 자체 개발한 웹 애플리케이션과 Rstudio Addins을 사용하여 간단히 Table 1을 만들어 볼 것이다(Figure @ref(fig:appgif), @ref(fig:addingif)).
연속 변수의 그룹 비교
연속 변수의 그룹 비교는 2 그룹일 때는 t-test, 3 그룹 이상이면 ANOVA라고 생각하면 되며, 2 그룹일 때 ANOVA 결과는 t-test 결과와 거의(?) 같다. 따라서 연속 변수는 무조건 ANOVA라고 생각해도 대충 맞다.
T-test
T-test는 2 그룹의 평균값을 비교하는 통계 방법1으로 필요한 숫자는 각 그룹의 평균과 분산이다. 실제로 데이터 없이 두 그룹의 평균과 분산만 있어도 t-test를 수행할 수 있으며 https://www.evanmiller.org/ab-testing/t-test.html 를 통해 웹에서도 간단히 계산할 수 있다. 아래 남녀의 총 콜레스테롤 데이터를 이용해 t-test를 수행해 보자.
이제 t.test 함수를 이용하여 남녀의 총 콜레스테롤 수치를 비교한다.
nev.ttest <- t.test(tChol ~ sex, data = data.t, var.equal = F)
nev.ttest
Welch Two Sample t-test
data: tChol by sex
t = -1.9211, df = 27.992, p-value = 0.06496
alternative hypothesis: true difference in means between group Female and group Male is not equal to 0
95 percent confidence interval:
-48.410207 1.553065
sample estimates:
mean in group Female mean in group Male
134.5714 158.0000 여자의 평균 콜레스테롤 값은 134.6, 남자는 158 이고 \(p\)-value는 0.065임을 확인할 수 있다.
위의 t.test 함수의 옵션 중 var.equal = F는 등분산 가정 없이 분석하겠다는 뜻으로 옵션을 적지 않아도 기본적으로 F가 적용된다. 등분산 가정이란 두 그룹의 분산이 같다고 가정하는 것인데, 계산이 좀 더 쉽다는 이점이 있으나 아무 근거 없이 분산이 같다고 가정하는 것은 위험한 가정이다. 위의 분석에 var.equal = T를 적용해보자.
ev.ttest <- t.test(tChol ~ sex, data = data.t, var.equal = T)
ev.ttest
Two Sample t-test
data: tChol by sex
t = -1.9007, df = 28, p-value = 0.06767
alternative hypothesis: true difference in means between group Female and group Male is not equal to 0
95 percent confidence interval:
-48.677187 1.820044
sample estimates:
mean in group Female mean in group Male
134.5714 158.0000 앞서는 Welch t-test였는데 이름이 바뀐 것을 확인할 수 있고 \(p\)-value도 0.068로 아까와 다르다. 논문 리뷰어가 요구하는 등의 특별한 경우가 아니고서야 위험한 등분산가정을 할 필요가 없고, 이제부터 var.equal 옵션은 신경쓰지 않아도 좋다.
ANOVA2
3 그룹 이상일 때는 2그룹씩 짝을 지어서 t-test를 여러 번 수행할 수 있다. 그러나 Table 1에서는 대부분 하나의 \(p\)-value만 제시하고 이것은 전체적으로 튀는 것이 하나라도 있는가?를 테스트하는 ANOVA를 이용한다.3 ANOVA는 비교할 모든 그룹에서 분산이 같다는 등분산 가정 하에 분석을 수행하며, 실제로 2 그룹일 때 ANOVA를 수행하면 등분산 가정 하에 수행한 t-test와 동일한 결과를 얻는다. 위에도 언급했듯이 모든 그룹에서 분산이 같다는 것은 너무 위험한 가정이나, 3 그룹 이상인 경우 마땅한 대안이 없고 Table 1에서 엄밀한 통계를 요구하는 것도 아니기 때문에 그냥 ANOVA를 쓰는 것이 관행이다. 아래 세 그룹의 총 콜레스테롤 데이터를 활용해 분석을 수행해 보자.
이제 aov함수를 이용하여 3 그룹의 평균 콜레스테롤 값을 한번에 비교한다.
Df Sum Sq Mean Sq F value Pr(>F)
group 2 1546 773.0 0.78 0.468
Residuals 27 26751 990.8 결과에서 나온 \(p\)-value인 0.468가 Table 1에 이용되며 의미는 “3 그룹에서 총콜레스테롤 값이 비슷하다(다른 것이 있다고 할 수 없다)” 이다.
비모수 통계: 정규분포 아닐 때
T-test나 ANOVA는 모두 변수가 정규분포를 이룬다고 가정하고 분석을 수행하는데, 언뜻 생각하기에 의학에서 정규분포가 아닌 변수는 없을 것 같지만4 일부 지표(ex: CRP, 자녀 수)들은 정규분포를 따르지 않는다고 알려져 있다. 이 때는 변수의 값 자체가 아닌 순위 정보만을 이용하는 비모수 검정을 이용한다. T-test에 대응되는 비모수 분석은 Wilcoxon rank-sum test 혹은 Mann–Whitney U test 로 불리며 앞서 이용한 남녀별 총 콜레스테롤 데이터로 분석을 수행하면 아래와 같다.
res.wilcox <- wilcox.test(tChol ~ sex, data = data.t)
res.wilcox
Wilcoxon rank sum test with continuity correction
data: tChol by sex
W = 72.5, p-value = 0.1046
alternative hypothesis: true location shift is not equal to 0위 결과에서 \(p\)-value는 0.105임을 확인할 수 있다. ANOVA에 대응되는 비모수 분석은 Kruskal–Wallis one-way ANOVA이며 역시 앞서 이용한 그룹별 총 콜레스테롤 데이터에 적용하면 아래와 같다.
res.kruskal <- kruskal.test(tChol ~ group, data = data.aov)
res.kruskal
Kruskal-Wallis rank sum test
data: tChol by group
Kruskal-Wallis chi-squared = 2.0192, df = 2, p-value = 0.3644마찬가지로 \(p\)-value는 0.364임을 확인할 수 있다.
범주형 변수의 그룹 비교
범주형 변수의 그룹 비교는 그룹 수나 정규분포를 고려할 필요가 없어 연속 변수일 때보다 훨씬 간단하며 딱 하나, 샘플 수가 충분한지만 확인하면 된다.
샘플 수 충분: Chi-square test
Chi-square test는 두 범주형 변수가 관계가 있는지 없는지를 파악하는 테스트로5 아래의 혈압약과 당뇨약 복용 여부를 조사한 데이터로 분석을 수행해 보겠다.
두 약물 복용 여부를 테이블로 나타내면
tb.chi <- table(data.chi)
tb.chi DM_medi
HTN_medi 0 1
0 15 13
1 14 8이며 언뜻 봐서는 관계가 있는지 아닌지 잘 모르겠다. 이제 chisq.test함수를 이용해서 Chi-square test를 수행하자.
res.chi <- chisq.test(tb.chi)
res.chi
Pearson's Chi-squared test with Yates' continuity correction
data: tb.chi
X-squared = 0.18246, df = 1, p-value = 0.6693\(p\)-value는 0.669가 나오고 혈압약 복용과 당뇨약 복용은 유의한 관계가 없다고 말할 수 있다.
샘플 수 부족: Fisher’s exact test
이번엔 다른 사람들의 혈압, 당뇨약 복용 데이터로 chi-square test를 수행해 보겠다.
아까와 마찬가지로 테이블로 두 약물 복용상태를 비교하면 아래와 같다.
tb.fisher <- table(data.fisher)
tb.fisher DM_medi
HTN_medi 0 1
0 31 8
1 9 2혈압약과 당뇨약을 모두 복용한 사람이 2명으로 좀 작아보이지만 무시하고 chi-square test를 수행하면 결과는 나오나 Warning 메시지가 뜬다.
chisq.test(tb.fisher)Warning in chisq.test(tb.fisher): Chi-squared approximation may be incorrect
Pearson's Chi-squared test with Yates' continuity correction
data: tb.fisher
X-squared = 4.5971e-31, df = 1, p-value = 1이는 두 약을 모두 복용한 사람이 2명뿐이라서 일어나는 문제로, 일반적으로 분석할 테이블에서 샘플 수가 너무 작은 항이 있으면 chi-square test의 계산이 부정확해진다. 이 때는 fisher’s exact test를 수행하며 아래와 같이 fisher.test함수를 이용하면 된다.
res.fisher <- fisher.test(tb.fisher)
res.fisher
Fisher's Exact Test for Count Data
data: tb.fisher
p-value = 1
alternative hypothesis: true odds ratio is not equal to 1
95 percent confidence interval:
0.07627205 5.55561549
sample estimates:
odds ratio
0.8636115 \(p\)-value는 1로 확인되고 마찬가지로 혈압약 복용과 당뇨약 복용은 유의한 관계가 없다고 할 수 있다.
여기서 의문점이 들 수 있다. 무조건 fisher’s test만 하면 간단한데 도대체 chi-square test는 왜 하는 것일까? 샘플 수가 작을 때는 fisher’s test만 하는 것이 실제로 더 간단하고 방법론적으로도 아무 문제가 없다. 그러나 샘플 수나 그룹 수가 늘어날수록 fisher’s test는 필요한 계산량이 급격하게 증가하는 문제가 있어 chi-square test를 먼저 수행하는 것을 권유한다.
추가: 짝지은 2 그룹
각 사람의 혈압을 한 번은 사람이 직접, 한 번은 자동혈압계로 측정했다고 하자. 이 때 직접 잰 혈압과 자동혈압계의 측정값을 비교한다면 t-test로 충분할까? t-test는 혈압 재는 방법마다 평균을 먼저 구한 후 그것이 같은지를 테스트하므로 짝지은 정보를 활용하지 못한다. 이 때는 각 사람마다 두 혈압값의 차이를 먼저 구한 후 평균이 0인지를 테스트하면, 짝지은 정보를 활용하면서 계산도 더 간단한 방법이 된다.
연속변수: Paired t-test
위에 언급한 대로 각 사람마다 차이값을 먼저 구한 후 그 평균이 0인지를 테스트하는 방법이 paired t-test이다. 아래의 수축기 혈압 데이터를 통해 t-test와의 차이점을 알아보자.
위 데이터는 30명의 사람이 앞서 말한 두 가지 방법으로 수축기 혈압을 측정한 데이터이다. 먼저 t-test를 수행하자.
pt.ttest <- t.test(data.pt$SBP_hand, data.pt$SBP_machine)
pt.ttest
Welch Two Sample t-test
data: data.pt$SBP_hand and data.pt$SBP_machine
t = -0.45768, df = 57.863, p-value = 0.6489
alternative hypothesis: true difference in means is not equal to 0
95 percent confidence interval:
-3.224307 2.024307
sample estimates:
mean of x mean of y
125.0 125.6 위 결과를 보면 각 방법의 평균을 먼저 구한 후 그것을 비교한 것을 확인할 수 있고 \(p\)-value는 0.649이다. 이제 paired t-test를 수행하자.
pt.ttest.pair <- t.test(data.pt$SBP_hand, data.pt$SBP_machine, paired = TRUE)
pt.ttest.pair
Paired t-test
data: data.pt$SBP_hand and data.pt$SBP_machine
t = -0.46171, df = 29, p-value = 0.6477
alternative hypothesis: true mean difference is not equal to 0
95 percent confidence interval:
-3.257804 2.057804
sample estimates:
mean difference
-0.6 이번에는 사람마다 차이값을 먼저 구한 후 그것이 0인지 테스트 한 것을 확인할 수 있고 \(p\)-value는 0.648이다.
Paired t-test의 비모수버전은 wilcoxon-signed rank test 이며 아래와 같이 실행한다.
pt.wilcox.pair <- wilcox.test(data.pt$SBP_hand, data.pt$SBP_machine, paired = TRUE)Warning in wilcox.test.default(data.pt$SBP_hand, data.pt$SBP_machine, paired =
TRUE): cannot compute exact p-value with tiesWarning in wilcox.test.default(data.pt$SBP_hand, data.pt$SBP_machine, paired =
TRUE): cannot compute exact p-value with zeroespt.wilcox.pair
Wilcoxon signed rank test with continuity correction
data: data.pt$SBP_hand and data.pt$SBP_machine
V = 214, p-value = 0.9482
alternative hypothesis: true location shift is not equal to 0본 강의에서는 다루지 않겠지만 짝지은 3개 이상의 그룹은 repeated measure ANOVA6라는 방법을 이용한다.
범주형 변수: Mcnemar test, Symmetry test for a paired contingency table
이번에는 측정값이 0,1과 같은 범주형 변수인 경우를 살펴보자. 아래 데이터를 활용해 약 복용 전후로 복통증상 발생에 차이가 있는지 알아본다고 하자.
이 데이터를 2 by 2 테이블로 정리하면 아래와 같다.
table.mc <- table(data.mc)
table.mc Pain_after
Pain_before 0 1
0 8 8
1 9 5먼저 앞서 배운 Chi-sqaure test 를 이용한 결과를 보자.
mc.chi <- chisq.test(table.mc)
mc.chi
Pearson's Chi-squared test with Yates' continuity correction
data: table.mc
X-squared = 0.17514, df = 1, p-value = 0.6756이것은 약 복용 전 복통 증상과 복용 후의 복통 증상이 얼마나 관계가 있는지 알아보는 테스트로 짝지은 정보를 활용하지 않는다. 이번엔 짝지은 정보를 활용하는 mcnemar test를 수행하자.
mc.mcnemar <- mcnemar.test(table.mc)
mc.mcnemar
McNemar's Chi-squared test with continuity correction
data: table.mc
McNemar's chi-squared = 0, df = 1, p-value = 1Mcnemar test는 약 복용후 증상발생이 달라진 사람 즉, discordant pair만 분석에 이용한다. 따라서 condordant pair 의 구성과 어떻더라도 통계결과는 동일하게 나온다.
한편 측정값이 3개 이상일 때는 chi-square test는 그대로 이용할 수 있으나, mcnemar test는 그대로 쓰지 못하고 symmetry test for a paired contingency table7라는 일반화된 테스트를 사용한다. 본 강의에서는 간단한 실행법만 살펴볼 것이며 먼저 rcompanion R package를 설치하자.
## For symmmetry test
#install.packages("rcompanion")
library(rcompanion)예제 테이블(3 \(\times\) 3)을 아래와 같이 불러온 후
## Example data
data(AndersonRainGarden)
AndersonRainGarden Yes.after No.after Maybe.after
Yes.before 6 0 1
No.before 5 3 7
Maybe.before 11 1 12nominalSymmetryTest 함수로 분석을 수행한다.
## Symmetry test
nominalSymmetryTest(AndersonRainGarden)$Global.test.for.symmetry
Dimensions p.value
1 3 x 3 0.000476
$Pairwise.symmetry.tests
Comparison p.value p.adjust
1 Yes.before/Yes.after : No.before/No.after 0.0736 0.0771
2 Yes.before/Yes.after : Maybe.before/Maybe.after 0.00937 0.0281
3 No.before/No.after : Maybe.before/Maybe.after 0.0771 0.0771
$p.adjustment
Method
1 fdr
$statistical.method
Method
1 McNemar test실습
웹 애플리케이션
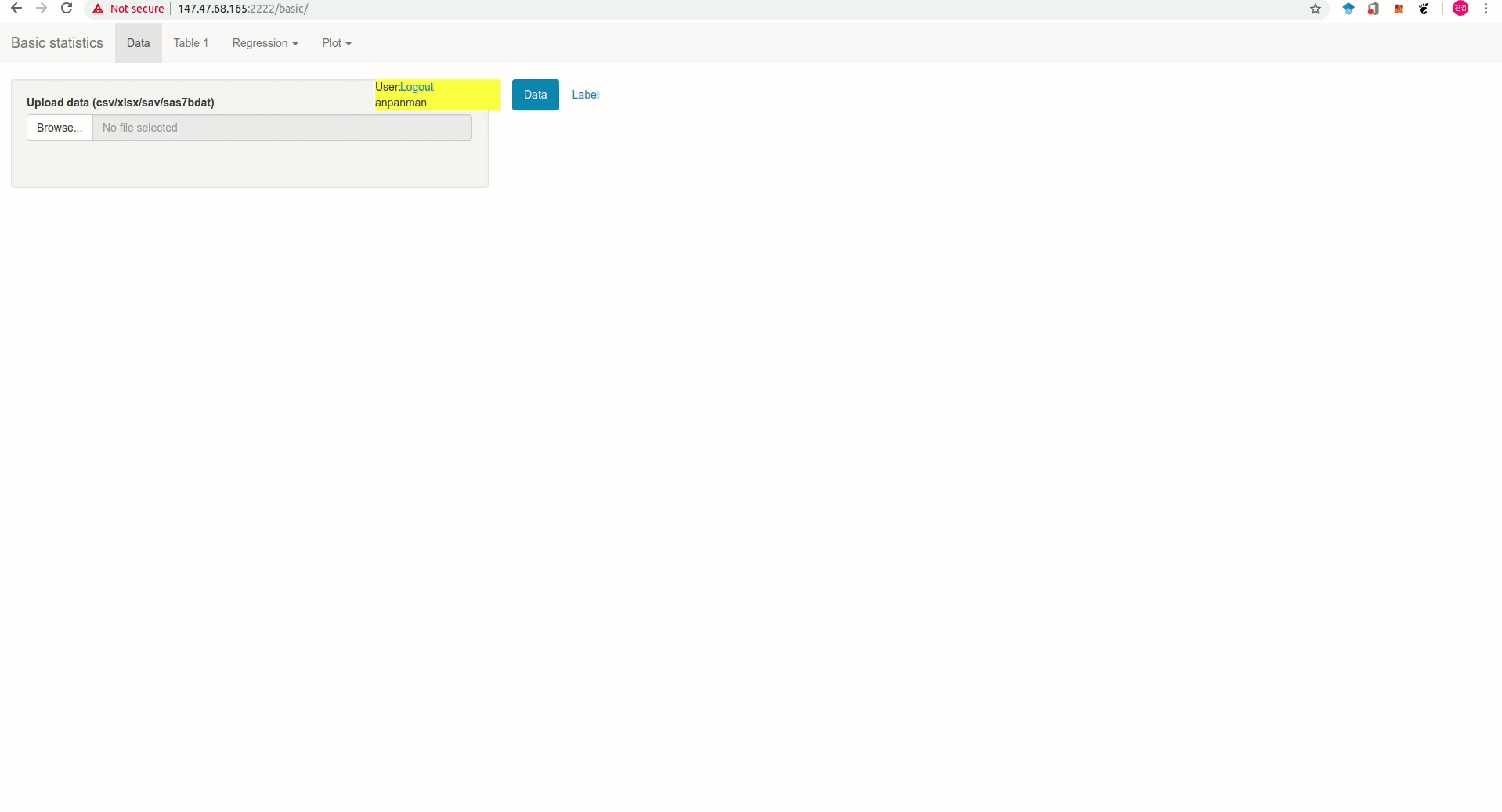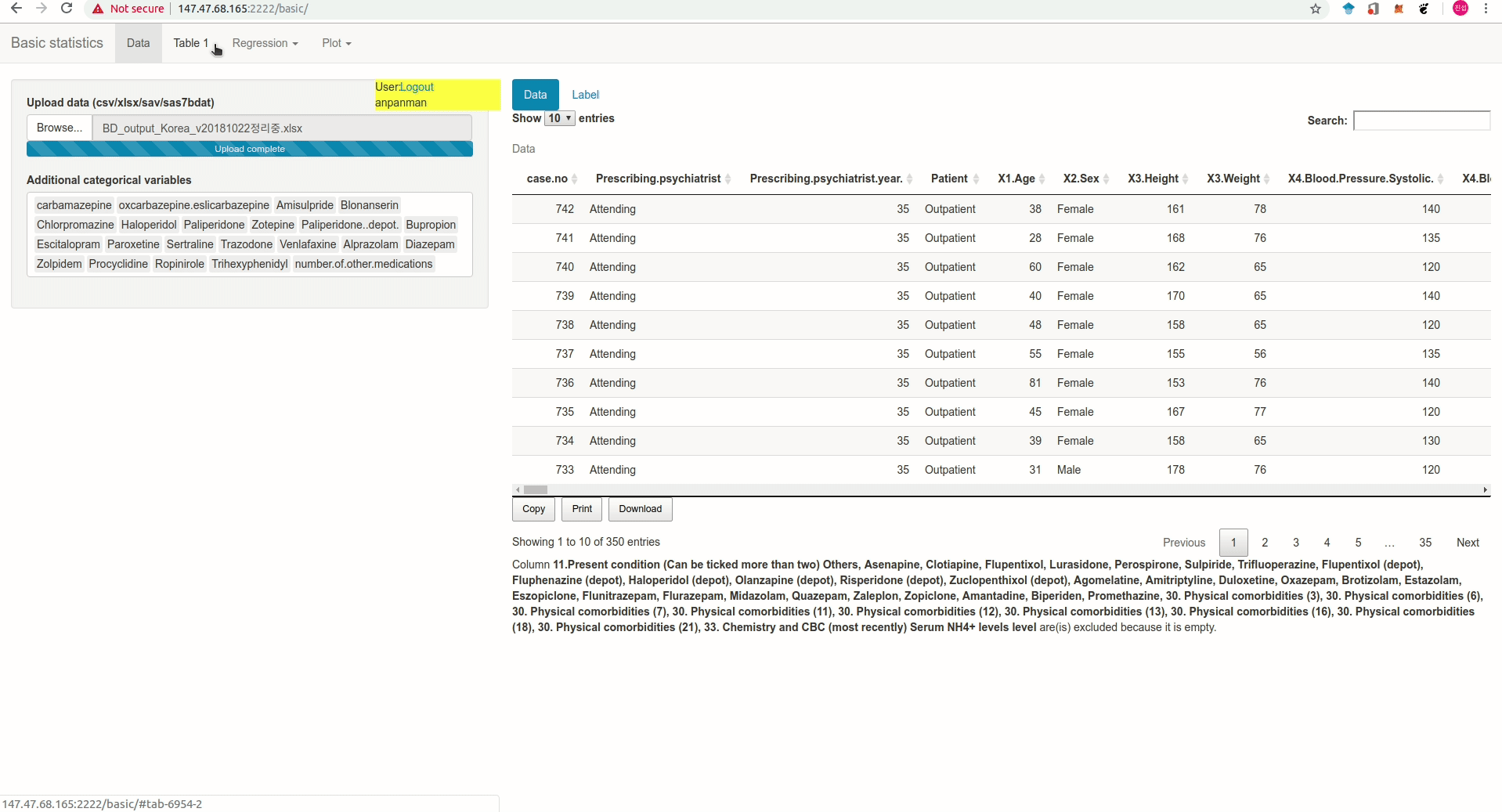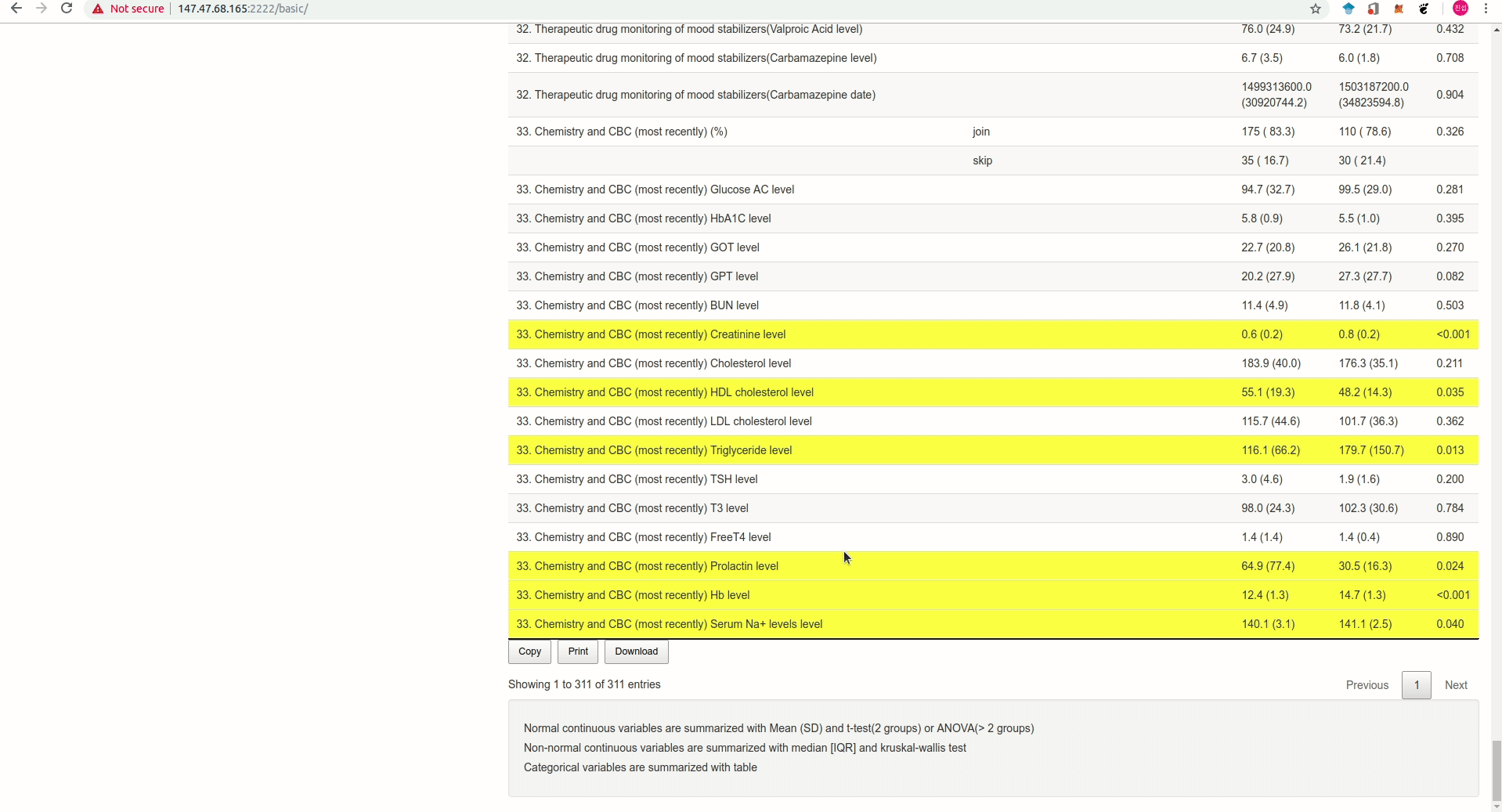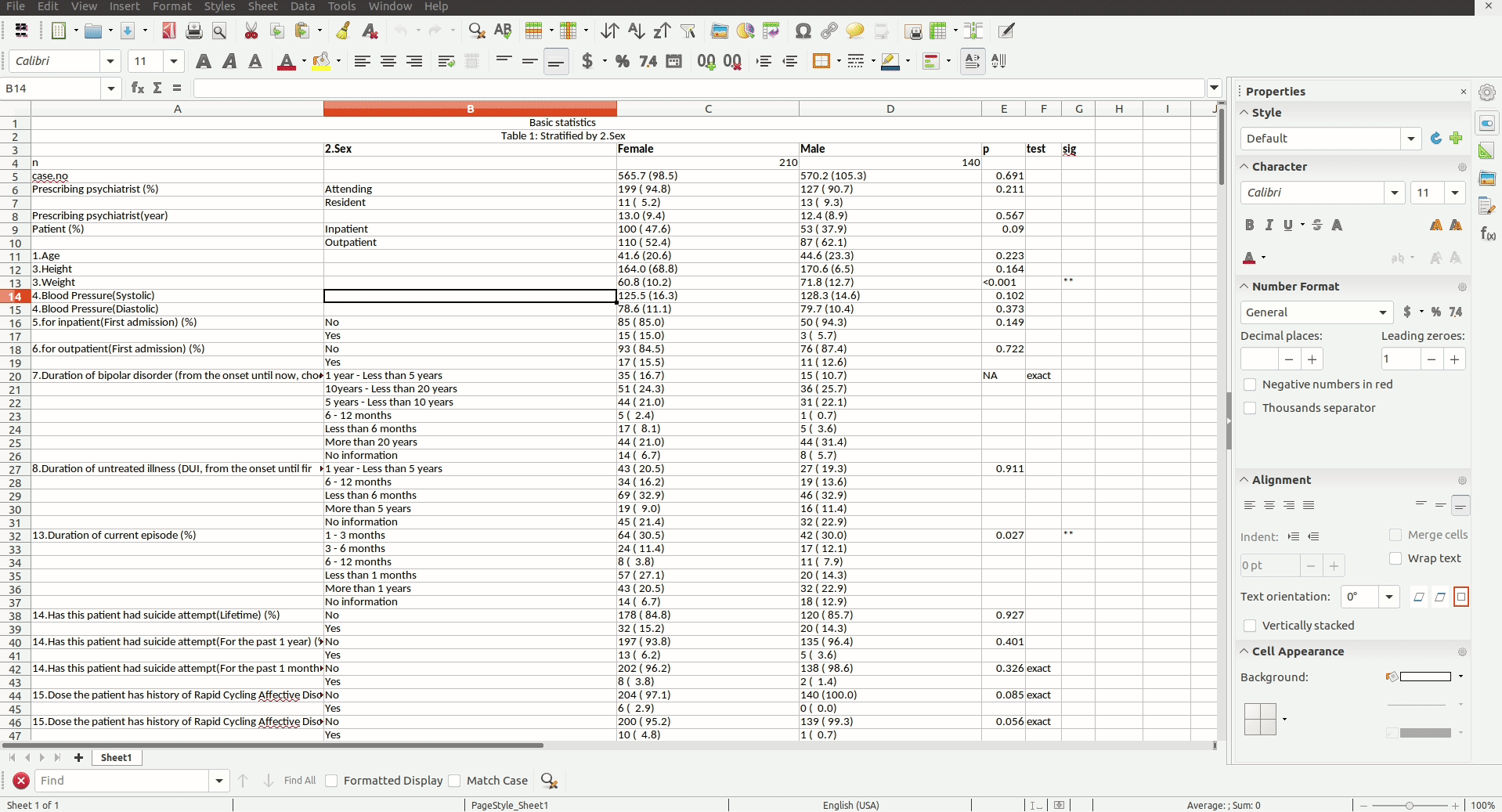
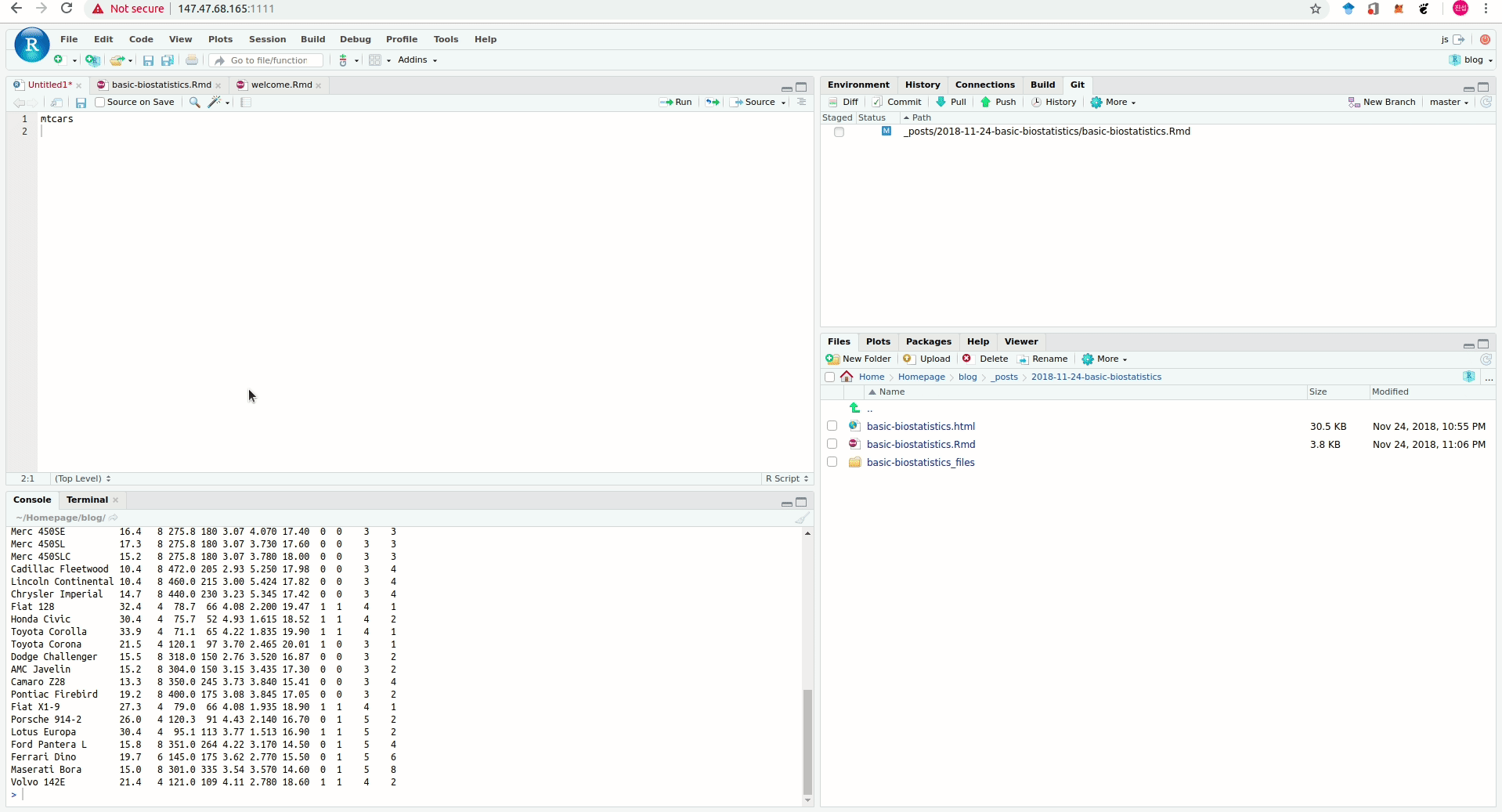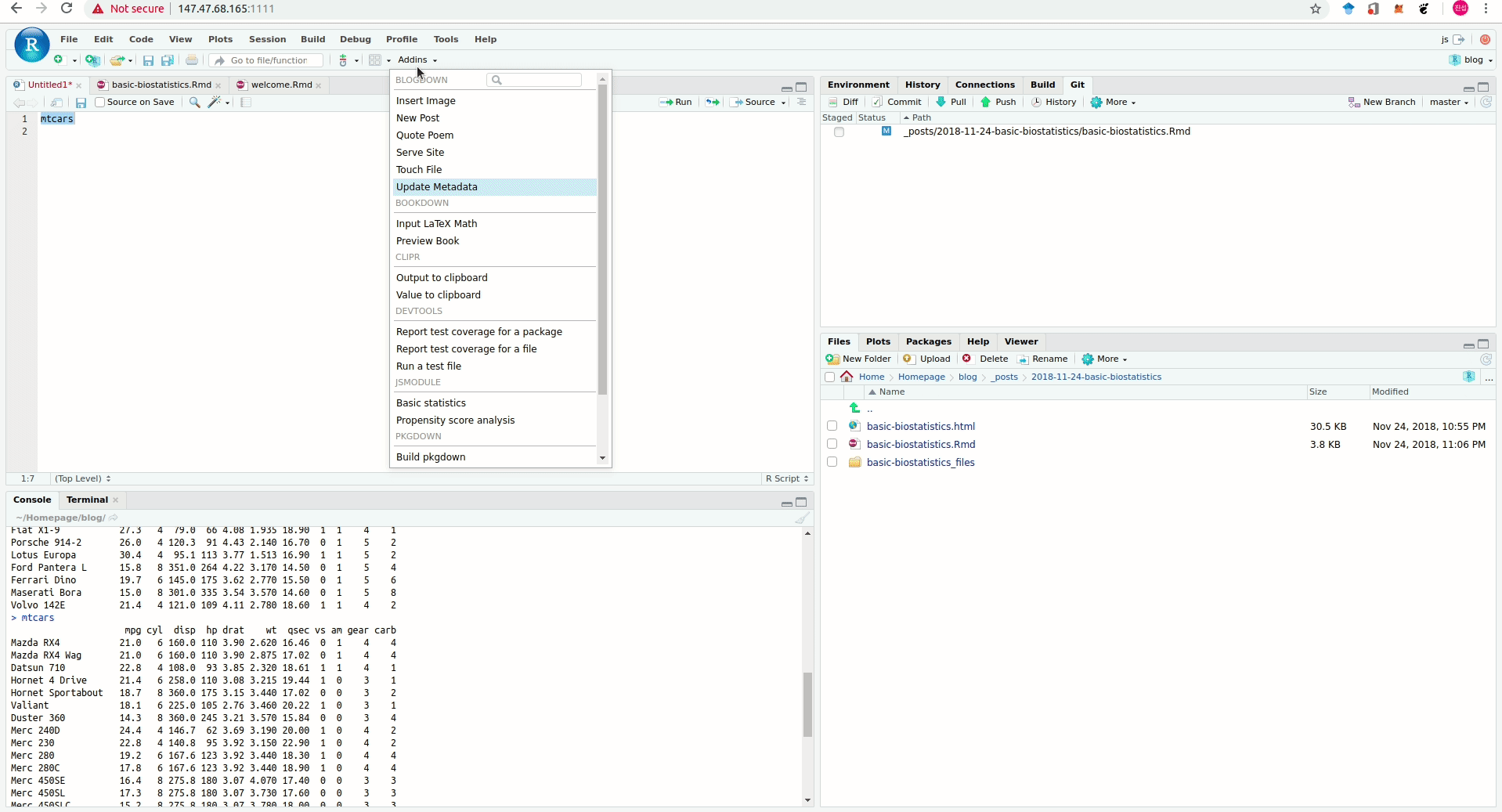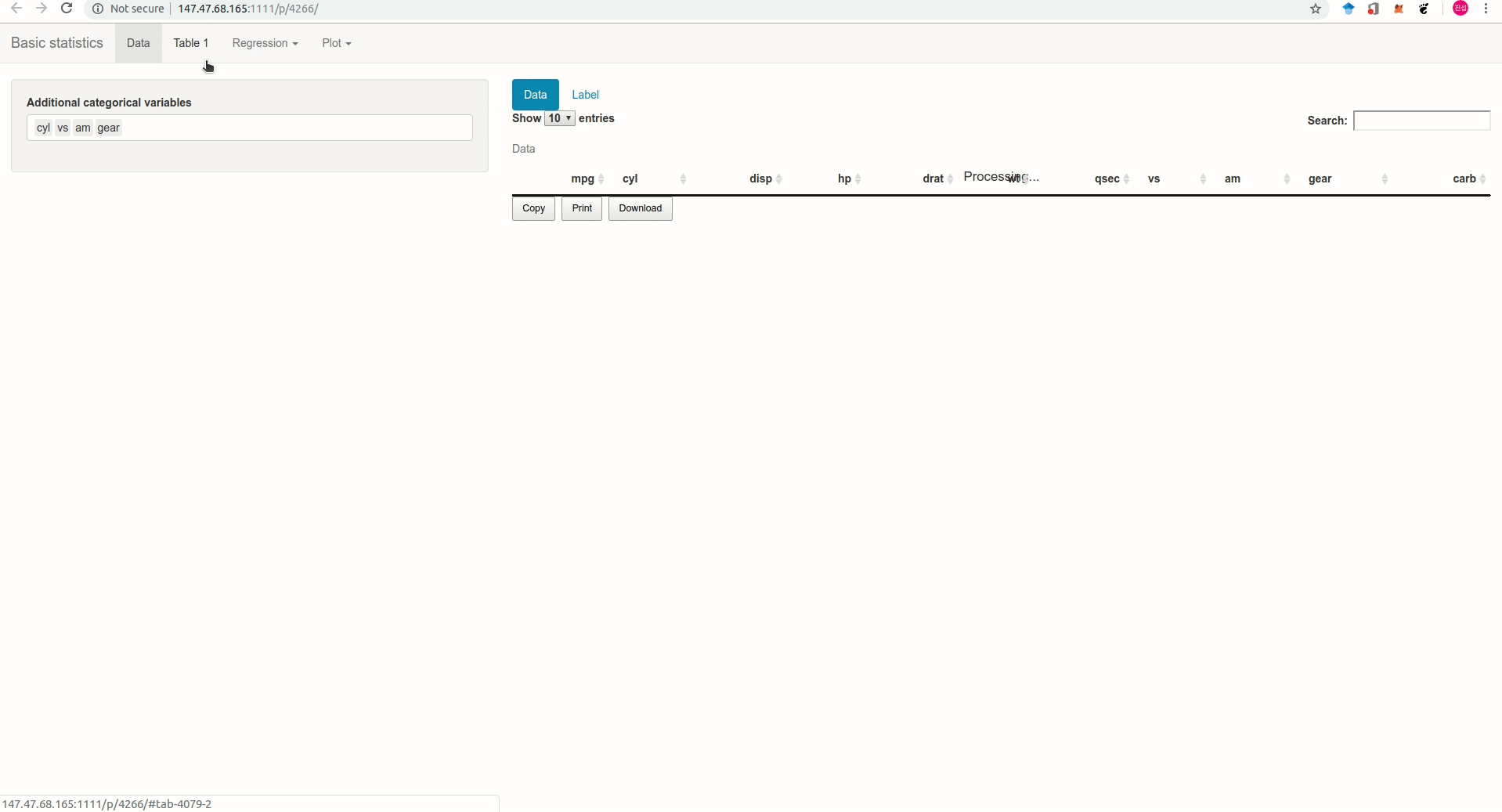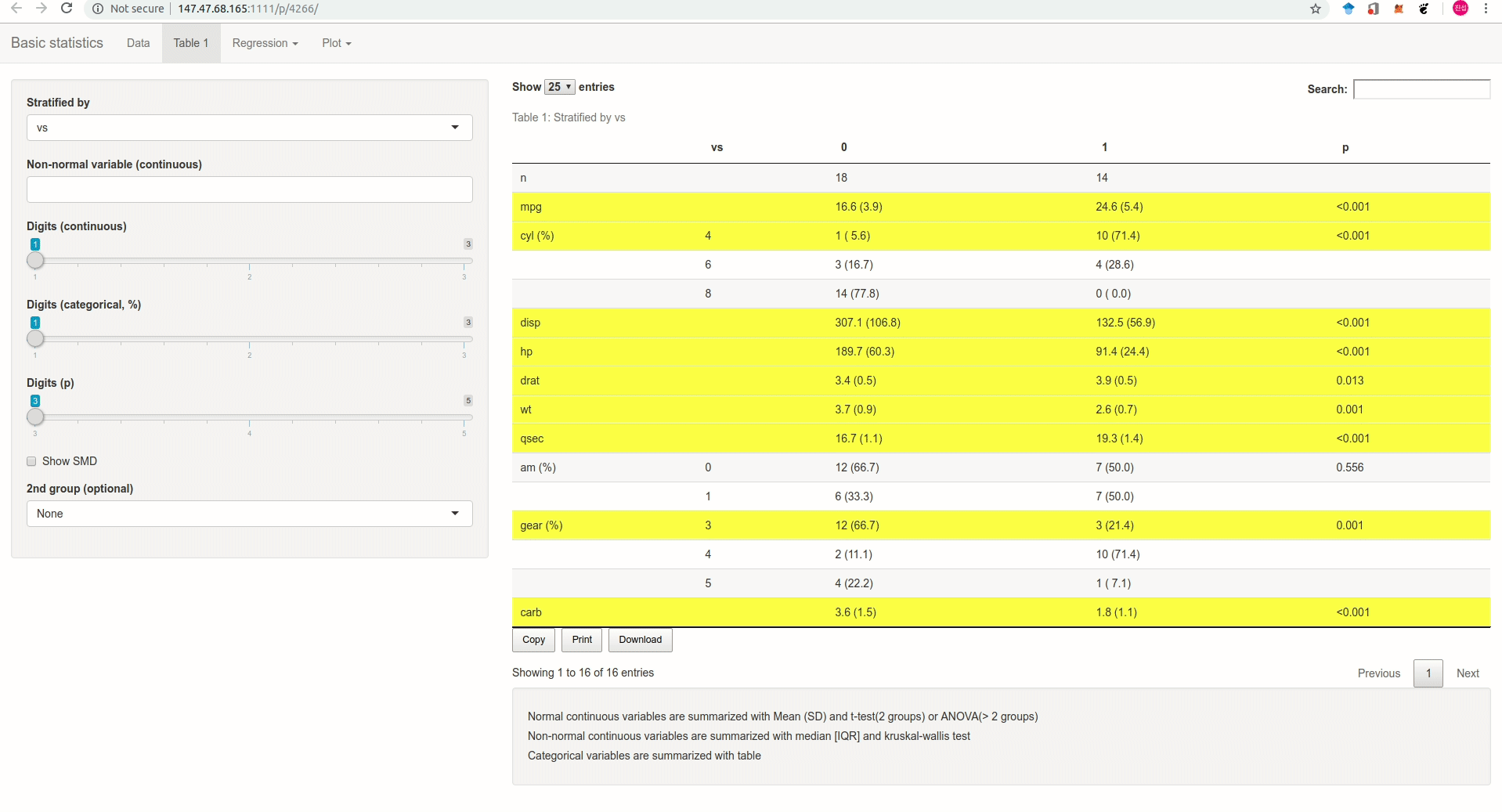
Anpanman 에서 만든 기초통계 앱을 소개한다(Figure @ref(fig:appgif)). 5메가 이하의 excel, csv 형태 혹은 sas, spss 프로그램으로 만든 데이터를 업로드하면 Table 1과 회귀분석, 로지스틱 회귀분석을 간단하게 수행하고 결과를 excel로 바로 다운받을 수 있다.
Rstudio Addins
5메가보다 큰 데이터는 R에서 데이터를 읽은 후, 자체적으로 만든 jsmodule R package를 설치하여 앱을 이용할 수 있다.
## For private package install
install.packages("devtools")
devtools::install_github(c("jinseob2kim/jstable", "jinseob2kim/jsmodule")) 패키지를 설치한 후 Rstudio 프로그램의 Addins 탭을 누르면 Basic statistics 항목이 보일 것이다. 데이터를 읽고 그것의 이름을 드래그 한 상태로 Basic statistics 를 누르면 된다(Figure @ref(fig:addingif)).
직접 R에서 코드를 실행하고 싶은 유저는 tableone R package를 참고하기 바란다.
마치며
지금까지 의학 연구에서 쓰이는 그룹 비교 통계들을 알아보고 웹 앱과 Rstudio Addins 을 이용하여 직접 Table 1을 만들어보았다. 앞으로 연구자들은 어려운 통계 프로그램을 이용할 필요 없이 Anpanman의 서비스를 활용, 빠르게 통계 분석을 수행하고 테이블과 그림을 바로 다운받을 수 있다.
References
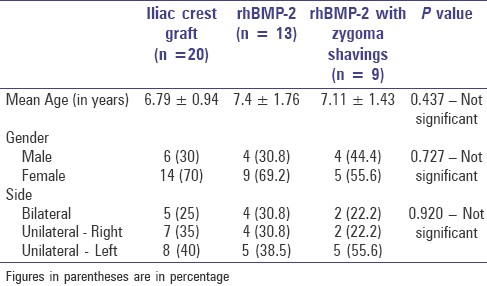
Balaji, SM. 2011. “Alveolar Cleft Defect Closure with Iliac Bone Graft, rhBMP-2 and rhBMP-2 with Zygoma Shavings: Comparative Study.” Annals of Maxillofacial Surgery 1 (1): 8. https://doi.org/10.4103/2231-0746.83144.
Footnotes
1 그룹의 평균값을 특정 숫자와 비교할 수도 있다.↩︎
본 강의에서는 One-way ANOVA만 다룬다.↩︎
사후(post-hoc) 분석을 이용, 어떤 것이 튀는지를 알아볼 수도 있다.↩︎
정규분포에 대한 내용은 https://jinseob2kim.github.io/Normal_distribution.html 를 참고하기 바란다.↩︎
세 범주형 변수일 때도 이용할 수 있으나 본 강의에서는 생략한다.↩︎
https://statistics.laerd.com/statistical-guides/repeated-measures-anova-statistical-guide.php↩︎
http://rcompanion.org/handbook/H_05.html↩︎
https://github.com/jinseob2kim/jsmodule↩︎
Citation
BibTeX citation:
@online{kim2018,
author = {Kim, Jinseob},
title = {의학 {연구에서의} {기술} {통계} with {R}},
date = {2018-11-28},
url = {https://blog.zarathu.com/posts/2018-11-24-basic-biostatistics/},
langid = {en}
}
For attribution, please cite this work as:
Kim, Jinseob. 2018. “의학 연구에서의 기술 통계 with R.”
November 28. https://blog.zarathu.com/posts/2018-11-24-basic-biostatistics/.