Cox 모델이란 ?
Cox 모델의 등장
Cox 모델은 위험 함수의 구조를 다음과 같이 정의했습니다. \[ h(t∣X)=h_0 (t) ⋅ \exp(\beta^T X) \]
이 식을 하나하나 풀어보면,
\(h(t∣X)\): 시간 \(t\)에서 공변량 \(X\)를 가진 사람의 위험도
\(h_0(t)\): baseline hazard function
→ 공변량이 모두 0일 때의 ‘기본 위험’ (시간에 따라 변함)\(\exp(\beta^T X)\): 변수 X가 위험도에 미치는 영향 (비례 계수)
이 구조가 바로 Cox 비례위험모형입니다.
Cox 모델의 핵심 특징
baseline hazard \(h_0(t)\)는 자유롭게 놔둠 → Cox 모델은 시간에 따른 위험 패턴을 미리 정하지 않습니다.
회귀계수 \(\beta\)만 추정 → 변수(예: 나이, 성별, 질병 유무)가 사건 발생 속도에 어떻게 영향을 주는 지를 파악합니다.
위험비를 바로 해석할 수 있음 \[ \frac{h(t∣X_1)}{h(t∣X_2)}= \exp(\beta^T(X_1−X_2)) \] → 두 집단 간 위험률의 비율이 시간과 관계없이 일정하게 유지됩니다.
Cox 모델의 결과 해석
보통 결과는 아래와 같은 표로 나타납니다.
| 변수 | 계수 β | exp(β) (위험비) | 해석 |
|---|---|---|---|
| 나이 | 0.04 | 1.04 | 나이가 1세 많을수록 위험 4% 증가 |
| 성별(남성) | 0.65 | 1.91 | 남성의 위험이 여성보다 약 2배 |
해석의 중심은 hazard ratio (위험비)에 있습니다.
즉, “이 요인이 위험을 얼마나 증가시키는가?”를 정량적으로 보여주는 것이 Cox 모델의 핵심 목적입니다.
예측이 안 되는 이유
Cox 모델은 설계 자체가 비교에 초점이 맞춰져 있습니다. 회귀계수 \(\beta\) 추정에는 baseline hazard \(h_0 (t)\)가 필요하지 않기 때문입니다. 하지만 개별 생존 확률 \(S(t|X)\)를 계산하려면 \[ S(t|X) = \exp (-H_0 (t) ⋅ \exp(\beta ^T X)) \] 와 같이 계산해야 하는데, 이 수식에는 baseline hazard가 필수적입니다. 따라서, cox 모델은 baseline hazard를 직접 추정하지 않기 때문에 예측이 불가능했습니다.
baseline hazard는 어떻게 추정할까?
앞서 본 것처럼, Cox 모델은 회귀계수 \(\beta\)만 추정하고, baseline hazard \(h_0(t)\)는 남겨둡니다. 이것은 Cox 모델의 유연성과 강점이기도 하지만, 반대로 예측에는 반드시 \(H_0(t)\) (누적 baseline hazard)가 필요합니다.
Breslow 방식: 가장 널리 쓰이는 추정 방법
Norman Breslow는 1972년 Cox 논문에 대한 토론에서 baseline hazard를 추정할 수 있는 간단한 수식을 제안했습니다.
\[ \hat{H}_0(t) = \sum_{i: t_i \leq t} \frac{d_i}{\sum_{j \in R(t_i)} \exp\left( \hat{\beta}^\top X_j \right)} \]
| 기호 | 의미 |
|---|---|
| \(t_i\) | 사건이 발생한 시점 |
| \(d_i\) | 그 시점에 발생한 사건 수 |
| \(R(t_i)\) | 해당 시점에 생존해 있는 사람들 (위험집합) |
| \(\hat{\beta}\) | Cox 모델로 추정한 회귀계수 |
| \(X_j\) | 위험집합 내 개별 환자의 공변량 값 |
Breslow 방식의 핵심 아이디어
사건이 많이 발생한 시간은 위험도가 높고, 위험도가 높은 사람은 더 많이 위험에 기여한다
그래서 Breslow 방식은 사건 수를 위험도 총합에 따라 분배합니다.
- 위 식의 분자는 사건 수
- 분모는 살아있는 사람들의 위험도 총합
→ 이걸 시간 순으로 누적하면 \(H_0(t)\)가 됩니다.
직관적으로 정리해 보면
어떤 시간에 1명이 사망했다면, 그건 그 시점의 전체 위험도 중 한 부분이 사라진 것입니다.
위험도가 높았던 사람일수록 사건 발생이 그 사람 때문일 가능성이 크다고 봅니다.
그래서 hazard는
\(\text{사건 수} \div \text{그 시점 위험도 총합}\)
으로 계산합니다.
손으로 계산해보는 Breslow 방식
예제 데이터
| ID | 나이(X) | 생존 시간(time) | 사건 여부(status) |
|---|---|---|---|
| A | 60 | 5 | 1 (사망) |
| B | 65 | 7 | 1 (사망) |
| C | 70 | 7 | 1 (사망) |
| D | 55 | 9 | 0 (검열) |
| E | 62 | 9 | 1 (사망) |
공변량은 나이(X) 하나만 사용합니다.
Cox 회귀 계수 \(\hat \beta = 0.05\) 라고 가정합니다.
1단계: 각 환자의 위험도 계산
| ID | 나이 | 위험도 \(\exp(0.05 \cdot X)\) |
|---|---|---|
| A | 60 | \(\exp(3.0) \approx 20.09\) |
| B | 65 | \(\exp(3.25) \approx 25.79\) |
| C | 70 | \(\exp(3.5) \approx 33.12\) |
| D | 55 | \(\exp(2.75) \approx 15.64\) |
| E | 62 | \(\exp(3.1) \approx 22.20\) |
2단계: 사건 발생 시점 정리
\(t=5\) : A 사망 (1건)
\(t=7\) : B, C 사망 (2건)
\(t=9\) : E 사망 (1건)
3단계: 각 시점에서의 hazard 기여 계산
시간 = 5
위험집합 \(R(5)\) : A, B, C, D, E (모두 생존 중)
총 위험도 합: \(20.09+25.79+33.12+15.64+22.20=116.84\)
사건 수: 1
해당 시점의 기여:
\[\Delta H_0(5) = \frac{1}{116.84} \approx 0.00856\]
시간 = 7
위험집합 \(R(7)\) : B, C, D, E (A는 사망)
총 위험도 합: \(25.79+33.12+15.64+22.20=96.75\)
사건 수: 2
해당 시점의 기여:
\[\Delta H_0(7) = \frac{2}{96.75} \approx 0.02068\]
시간 = 9
위험집합 \(R(9)\) : D, E (B, C는 사망)
총 위험도 합: \(15.64+22.20=37.84\)
사건 수: 1
해당 시점의 기여:
\[\Delta H_0(9) = \frac{1}{37.84} \approx 0.02643\]
4단계: 누적 hazard 계산
\[ \hat H_0 (5) = 0.00856 \] \[ \hat H_0 (7) = 0.00856 + 0.02068 = 0.02924 \] \[ \hat H_0 (9) = 0.02924 + 0.02643 = 0.5567 \]
5단계: 생존확률 계산 예시 (예: D)
D의 위험도: \(\exp(0.05 \cdot 55) = \exp(2.75) \approx 15.64\)
누적 hazard: \(\hat{H}_0(9) = 0.05567\)
\[ S(9|D) = \exp(-0.05567 \cdot 15.64) = \exp(-0.871) \approx 0.418 \]
→ D가 9일까지 생존할 확률은 약 41.8%
[실전 R 코드] Cox 모델로 생존 예측 모델 만들기
앞서 배운 Breslow 방식으로 Baseline Hazard를 구해, 특정 환자 그룹의 생존 확률을 예상해 볼 수 있는 모델을 만들 수 있습니다. 아래는 그 예시입니다.
library(survival)
data(lung)
fit <- coxph(Surv(time, status) ~ age + sex, data = lung)
summary(fit)
basehaz_df <- basehaz(fit, centered = FALSE)
head(basehaz_df)
new_patient <- data.frame(age = 70, sex = 1)
lp <- predict(fit, newdata = new_patient, type = "lp")
basehaz_df$surv <- exp(-basehaz_df$hazard * exp(lp))
plot(basehaz_df$time, basehaz_df$surv, type = "l",
xlab = "Time", ylab = "Survival Probability",
main = "Predicted Survival Curve for New Patient")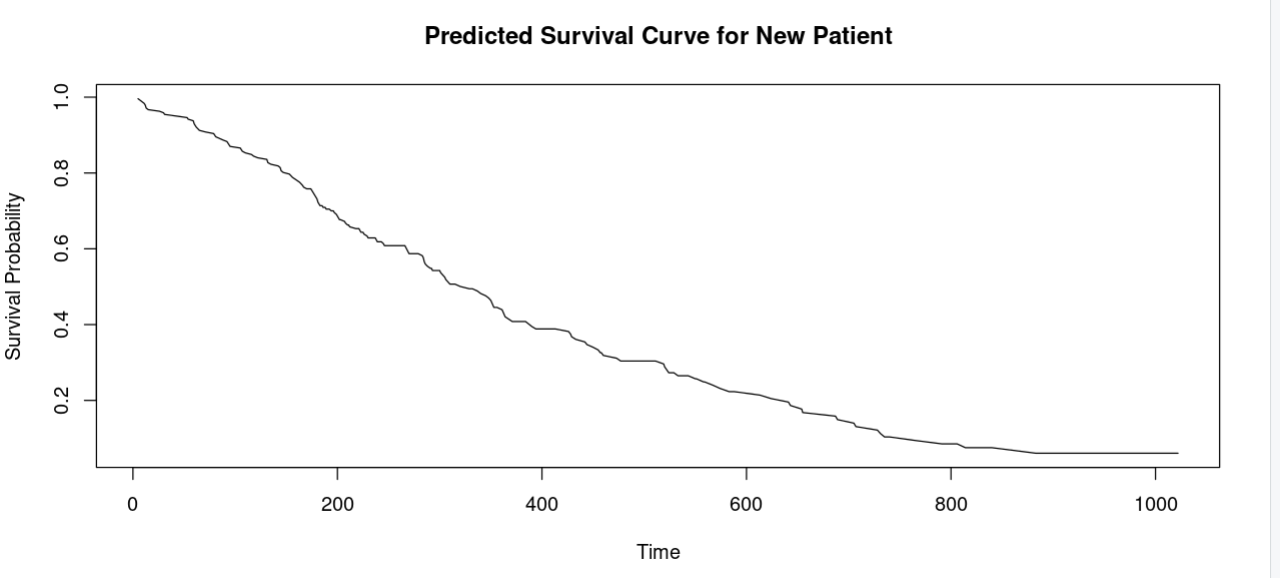
[더 알아보기] baseline hazard를 추정하는 다양한 방식
앞서 우리는 Breslow 방식으로 baseline hazard \(H_0(t)\)를 추정했습니다. 가장 널리 쓰이는 방법이기도 합니다. 하지만 실제 데이터는 그렇게 단순하지 않습니다.
예를 들어, 동시에 여러 사건이 발생하는 경우에는 Breslow 방식이 정확하지 않을 수 있습니다.
그래서 여러 가지 방식들이 제안되었고, R에서는 coxph() 함수의 ties 인자를 통해 이를 선택할 수 있습니다.
왜 다른 방식이 필요한가?
현실 데이터에서는 여러 명이 동일한 시간에 이탈하는 일이 자주 발생합니다. 이런 경우, 누가 먼저였는지 모르기 때문에 동시 사건 처리 방식이 중요합니다.
주요 방식 비교
| 방식 | 특징 | 동시사건 처리 | coxph() 옵션 |
사용 추천 상황 |
|---|---|---|---|---|
| Breslow | 기본값, 계산 간단 | 사건 수를 평균 분배 | "breslow" (기본값) |
동시사건이 적을 때 |
| Efron | 보정된 평균 방식 | 순차적으로 분배 | "efron" |
동시사건이 많을 때 |
| Exact | 순열 기반 정밀 추정 | 완전 계산 | "exact" |
표본이 작고 정확성이 중요한 경우 |
Breslow vs Efron의 핵심 차이
Breslow 방식
\(d\)건의 사건이 같은 시간에 발생하면, 그냥 \(\frac{d}{\sum \exp(\beta^T X)}\)과 같이 평균 분배
계산은 빠르지만, bias가 생길 수 있음
Efron 방식
사건을 하나씩 순차적으로 발생한 것처럼 나눠서 분자와 분모를 보정
보다 현실적인 근사 방식
\[ \Delta H_0(t) = \sum_{k=1}^{d} \frac{1}{\sum_{j \in R(t)} \exp(\beta^T X_j) - \frac{k - 1}{d} \sum_{j \in D(t)} \exp(\beta^T X_j)} \]
\(D(t)\) : 사건이 발생한 사람들
순차적으로 사건을 일으키면서 분모를 조정함
R 코드 예시 : Efron 방식 비교
코드 예시
library(survival)
fit_breslow <- coxph(Surv(time, status) ~ age + sex, data = lung, ties = "breslow")
fit_efron <- coxph(Surv(time, status) ~ age + sex, data = lung, ties = "efron")
# 두 모델의 회귀계수 비교
summary(fit_breslow)$coefficients
summary(fit_efron)$coefficients코드 결과
> summary(fit_breslow)$coefficients
coef exp(coef) se(coef) z Pr(>|z|)
age 0.01701289 1.0171584 0.009221954 1.844825 0.065063023
sex -0.51256479 0.5989574 0.167462063 -3.060782 0.002207601
> summary(fit_efron)$coefficients
coef exp(coef) se(coef) z Pr(>|z|)
age 0.01704533 1.017191 0.009223273 1.848078 0.064591012
sex -0.51321852 0.598566 0.167457962 -3.064760 0.002178445대부분의 경우 큰 차이는 없지만, 동시 사건이 많거나 위험도가 비슷한 경우에는 의미 있는 차이가 생깁니다.
기타 방식: Exact, Kalbfleisch-Prentice
Exact 방식은 모든 가능한 사건 순서를 계산하여 우도를 정확히 계산
→ 계산 비용이 높음, 작은 데이터셋에만 적합Kalbfleisch-Prentice 방식은 discrete-time hazard 추정용
→ R 기본에서는 잘 사용되지 않음
Reuse
Citation
@online{choi2025,
author = {Choi, Sungho},
title = {Breslow {방식을} {이용한} {Cox} {예측} {모델} {만들기}},
date = {2025-05-07},
url = {https://blog.zarathu.com/posts/2025-05-07-Breslow/},
langid = {en}
}