ICC는 무엇인가
Intraclass Correlation Coefficient (ICC)는 집단으로 구성된 단위들에 대해 수치 측정값이 주어졌을 때, 동일한 집단 내 단위들이 서로 얼마나 유사한지를 나타내는 기술 통계량이다. 주로 측정 신뢰도를 평가할 때 사용되며, 특히 동일한 대상에 대해 여러 관측자(또는 반복 측정)가 수행한 측정의 일관성을 평가하는 데 유용하다.
ICC는 일반적인 상관계수와 달리 짝지어진 관측값이 아니라, 그룹으로 구성된 데이터에 대해 계산된다는 점에서 차이가 있다.
ICC vs. Cohen’s Kappa
ICC와 Cohen’s Kappa는 모두 측정자 간 일치도를 측정하는 도구지만, 적용되는 데이터의 특성과 해석 방식에서 차이가 있다.
자료의 유형
- ICC는 연속형 변수에 사용됨
- Cohen’s Kappa는 범주형 변수에 사용됨
즉 ICC는 “얼마나 수치들이 서로 비슷한가?”를 보는 것이고, Cohen’s kappa는 “서로 같은 범주로 분류했는가?”를 보는 것이다.
평가방식
- ICC는 분산을 기반으로 측정값 간의 상관 관계(유사성)를 분석함.
- Cohen’s Kappa는 기대 일치도를 고려하여, 관측된 일치도와 우연히 일어날 수 있는 일치도의 차이를 보정함.
즉, ICC는 총 변동성 중에서 집단 내 일관성에 기인하는 부분의 비율을 나타내는 것이고, Cohen’s Kappa는 실제 일치가 단순히 우연에 의한 것이 아님을 보장해 주는 것이다.
측정자 수
- ICC는 둘 이상의 평가자에게 적용할 수 있음. 측정 모델에 따라 다양한 변형등이 존재함.
- Cohen’s Kappa는 전통적으로 두 평가자에 대한 일치도 측정에 사용되며, 다수 평가자일 경우에는 Fleiss’ kappa 등을 사용함.
ICC의 사용분야
- 심리학, 의학, 교육학 등에서 테스트 재현성 또는 평가자 간 신뢰도 분석
- 머신러닝/데이터 분석에서는 데이터 라벨링 일관성 확인
- 반복 측정 설계에서 측정의 안정성 검증
초기의 ICC
초기의 ICC 연구는 짝을 이루는 측정값에 초점을 맞췄으며, 처음 제안된 ICC 통계량은 Pearson 상관계수를 수정한 형태였다.
초기 ICC의 정의
Ronald Fisher가 제안한 초기 ICC는 다음과 같다.
\[ r = \sum_{n=1}^{N} \frac{(x_{n,1} - \bar{x})(x_{n,2} - \bar{x})}{Ns^2} \]
- 데이터셋은 \(N\)개의 짝으로 구성됨
- 각 개체 \(n\)에 대해 두 개의 측정값 \((x_{n,1} , x_{n,2})\)가 존재함
- \(\bar{x}\)는 전체 데이터의 평균 \[ \bar{x} = \frac{1}{2N} \sum_{n=1}^{N} (x_{n,1} + x_{n,2}) \]
- \(s^2\)은 전체 데이터의 분산 \[ s^2 = \frac{1}{2N} \left\{ \sum_{n=1}^{N} (x_{n,1} - \bar{x})^2 + \sum_{n=1}^{N} (x_{n,2} - \bar{x})^2 \right\} \]
| r 값 범위 | 신뢰도의 정도 |
|---|---|
| r ≤ 0.00 | Poor |
| 0.00 < r ≤ 0.20 | Slight |
| 0.20 < r ≤ 0.40 | Fair |
| 0.40 < r ≤ 0.60 | Moderate |
| 0.60 < r ≤ 0.80 | Substantial |
| 0.80 < r ≤ 1.00 | Almost Perfect |
Pearson 상관계수와 ICC의 차이점
Pearson 상관계수와 ICC는 모두 연속형 데이터를 비교할 때 사용하는 지표이지만, 그들이 측정하는 대상과 의미는 전혀 다르다.
먼저 Pearson 상관계수는 두 변수 간의 선형 관계(일관된 증가/감소)를 측정한다. 예를 들어, 키와 몸무게처럼, 한 변수가 커질수록 다른 변수도 함께 커지는 경향이 있는지를 파악할 때 유용하다. 이때 값은 -1에서 +1 사이이며, 1에 가까울수록 완벽한 양의 선형 관계를 의미한다. 하지만 이 지표는 값 자체의 차이는 고려하지 않는다.
반면 ICC는 동일한 대상을 여러 번 측정했을 때 그 값이 얼마나 비슷하게 나오는지를 측정하는 지표아다. 즉 서로 다른 평가자나 시간에 따라 측정값이 달라졌을 때, 그 변화가 개인의 특성 차이 때문인지, 아니면 측정자의 오차 때문인지를 분리할 수 있다. ICC 값은 일반적으로 0에서 1 사이에 있으며, 1에 가까울수록 일관되고 신뢰할 수 있는 측정이라고 해석할 수 있다.
중요한 차이는 해석의 포인트에 있다:
Pearson 상관계수는 측정값 간의 선형 관계만을 보기 때문에, 두 평가자가 항상 10점 차이를 주더라도 여전히 상관계수는 1이 될 수 있다.
하지만 ICC는 ‘값 자체가 얼마나 유사한지’를 보며, 위와 같은 상황에서는 일치도가 낮다고 판단한다. 즉 Pearson은 “패턴의 일관성”, ICC는 “값의 일치도”를 본다고 이해할 수 있다.
또한, Pearson 상관계수는 서로 다른 단위를 가진 두 변수(예: 키와 체중)에도 적용 가능하지만, ICC는 동일한 측정 단위 내에서만 적절하게 해석할 수 있다.
3개 이상의 값을 가진 그룹에서의 ICC
데이터셋이 각 그룹당 3개의 측정값을 가지는 경우, ICC는 다음과 같이 확장된다. \[ r = \frac{1}{3N s^2} \sum_{n=1}^{N} \left\{ (x_{n,1} - \bar{x})(x_{n,2} - \bar{x}) + (x_{n,1} - \bar{x})(x_{n,3} - \bar{x}) + (x_{n,2} - \bar{x})(x_{n,3} - \bar{x}) \right\} \]
- \(\bar{x}\)는 전체 평균 \[ \bar{x} = \frac{1}{3N} \sum_{n=1}^{N} (x_{n,1} + x_{n,2} + x_{n,3}) \]
- \(s^2\)는 전체 분산 \[ s^2 = \frac{1}{3N} \left\{ \sum_{n=1}^{N} (x_{n,1} - \bar{x})^2 + \sum_{n=1}^{N} (x_{n,2} - \bar{x})^2 + \sum_{n=1}^{N} (x_{n,3} - \bar{x})^2 \right\} \] 여기서, 그룹의 크기(K)가 커질수록, 계산 과정에서 고려해야 할 교차항의 수도 증가한다.
위 공식을 일반화하면 다음과 같아진다. \[ r = \frac{K}{K-1} \cdot \frac{1}{Ns^2} \sum_{n=1}^{N} (\bar{x}_n - \bar{x})^2 - \frac{1}{K-1} \]
- \(K\)는 그룹당 데이터 개수
- \(\bar{x_n}\)는 \(n\)번째 그룹의 평균
\(K=3\)을 대입하면 위 공식과 완벽히 같아진다. 위 공식에 따르면, ICC값은 항상 \(\frac{-1}{K-1}\)이상의 값을 가진다는 것을 알 수 있다. 따라서 ICC는 항상 \(-1 \leq r \leq 1\)의 범위 안에서 존재하지만, 데이터 개수(\(K\))가 많아질 수록 음수로 나올 가능성이 줄어든다.
또한 충분히 큰 \(K\)에 대해서, 다음과 같이 근사할 수도 있다. \[ r = \frac{K}{K-1} \cdot \frac{1}{Ns^2} \sum_{n=1}^{N} (\bar{x}_n - \bar{x})^2 \]
ICC의 해석 및 한계점
ICC는 총 분산 중에서 그룹 간 변동이 차지하는 비율로 해석할 수 있다.
이상적인 데이터에서는 ICC 값이 0~1 사이에 있어야 하지만, 실제 샘플 데이터에서는 음수 값이 나올 수도 있다. 이는 Ronald Fisher가 ICC를 편향되지 않은 추정량으로 설계했기 때문이다. 따라서 모집단에서 ICC가 0일 경우, 표본 데이터에서는 음수 값이 나올 수 있다.
ICC의 체계화
Shrout & Fleiss (1979)
Shrout & Fleiss는 초기의 ICC를 체계적으로 분류하였다. 3가지 모델 유형(Model 1, 2, 3), 2가지 측정 방식(1: single, k: 평균)으로 분류하여 총 6가지 유형의 ICC를 정의하였다.
모델 종류
- one-way random
- 피험자 간의 변동만을 고려하는 모형
- 피험자 간의 차이에 대한 평가지의 일치도를 평가할 때 사용함
- 평가자의 효과는 고려하지 않고, 단순히 피험자 간의 일관성을 평가할 때 사용함
- two-way random
- 피험자 간 변동뿐만이 아니라, 평가자 간의 변동도 고려하는 모형
- 동일한 피험자에 대해 평가한 결과가 얼마나 일치하는지, 평가자들 간의 평가 결과가 얼마나 일관성 있는 지를 평가할 때 사용함
- two-way mixed
- 피험자 간의 변동과 평가자 간의 변동을 고려하는 모형
- 특정 평가자들이 고정되어 있을 때, 피험자 간의 일치도를 평가하는 데 사용함
측정방식
- 단일 측도(single)
- 평가자 간에 얼마나 차이가 있는지 확인
- 각 평가자에 의해 한 번의 측정이 일어난 경우
- 평균 측도(average)
- 평균값과 얼마나 차이가 있는지 확인
- 각 평가자에 의해 여러 번 측정이 일어난 경우
McGraw & Wong (1996)
McGraw & Wong은 Shrout & Fleiss의 체계를 확장하여 총 10가지 ICC 형태를 정의하였다. 다음과 같은 총 3가지의 분류 기준을 제시하였다.
모델 종류
one-way random
two-way random
two-way mixed
측정방식
단일 측도(single)
평균 측도(average)
정의(Definition Agreement)
- 일치도(consistency)
- 상대적 순위/경향이 일치하는지를 의미
- 평가자 간의 체계적인 차이는 무시하고, 변동성만 분석
- 포함하는 오차 : 우연한 변동
- 사용 상황 : 평가자가 고정되어 있고, 상대적 순위가 중요한 경우
- 절대합의도(absolute agreement)
- 두 평가자의 결과가 완전히 같은지를 의미
- 평가자 간의 체계적인 차이까지도 고려
- 포함하는 오차 : 우연한 변동, 평가자 간 편향
- 사용 상황 : 정량적 측정이 실제 절대값의 일치도를 요구하는 경우
ICC 분류
아래의 표는 Shrout & Fleiss와 McGraw & Wong의 기준에 따라 ICC를 정리한 것이다.
| McGraw and Wong | Shrout and Fleiss | Formulas for Calculating ICC |
|---|---|---|
| One-way random effects, absolute agreement, single rater/measurment | ICC(1,1) | \(\frac{MS_R - MS_W}{MS_R +(k+1)MS_W}\) |
| Two-way random effects, consistency, single rater/measurment | - | \(\frac{MS_R - MS_E}{MS_R +(k-1)MS_E}\) |
| Two-way random effects, absolute agreement, single rater/measurment | ICC(2,1) | \(\frac{MS_R - MS_E}{MS_R +(k-1)MS_E + \frac{k}{n} (MS_C - MS_E )}\) |
| Two-way mixed effects, consistency , single rater/measurment | ICC(3,1) | \(\frac{MS_R - MS_E}{MS_R +(k-1)MS_E}\) |
| Two-way mixed effects, absolute agreement, single rater/measurment | - | \(\frac{MS_R - MS_E}{MS_R +(k-1)MS_E + \frac{k}{n} (MS_C - MS_E )}\) |
| One-way random effects, absolute agreement, multiple rater/measurment | ICC(1,k) | \(\frac{MS_R - MS_W}{MS_R}\) |
| Two-way random effects, consistency, multiple rater/measurment | - | \(\frac{MS_R - MS_E}{MS_R}\) |
| Two-way random effects, absolute agreement, multiple rater/measurment | ICC(2,k) | \(\frac{MS_R - MS_E}{MS_R + \frac{MS_C -MS_E}{n}}\) |
| Two-way mixed effects, consistency, multiple rater/measurment | ICC(3,k) | \(\frac{MS_R - MS_E}{MS_R}\) |
| Two-way mixed effects, absolute agreement, multiple rater/measurment | - | \(\frac{MS_R - MS_E}{MS_R + \frac{MS_C -MS_E}{n}}\) |
- \(k\) : 평가자 수
- \(n\) : 피험자 수
- \(MS_R\) : mean square for rows
- \(MS_W\) : mean square for residual sources of variance
- \(MS_E\) : mean square for error
- \(MS_C\) : mean square for columns
One-way 모델에서 Consistency가 정의 되지 않는 이유
One-way random model은 평가자 효과를 모델에 포함하지 않기 때문이다. One-way 모델에서는 오직 피험자 간 차이만 고려하기 때문에 평가자 간 차이가 분산 구조에서 빠져있다. 따라서 평가자 간 일관성을 측정할 수 없다. 결과적으로 One-way 모델은 “Agreement”는 가능하지만 “Consistency”는 정의할 수 없다.
ICC 방식을 정하는 법
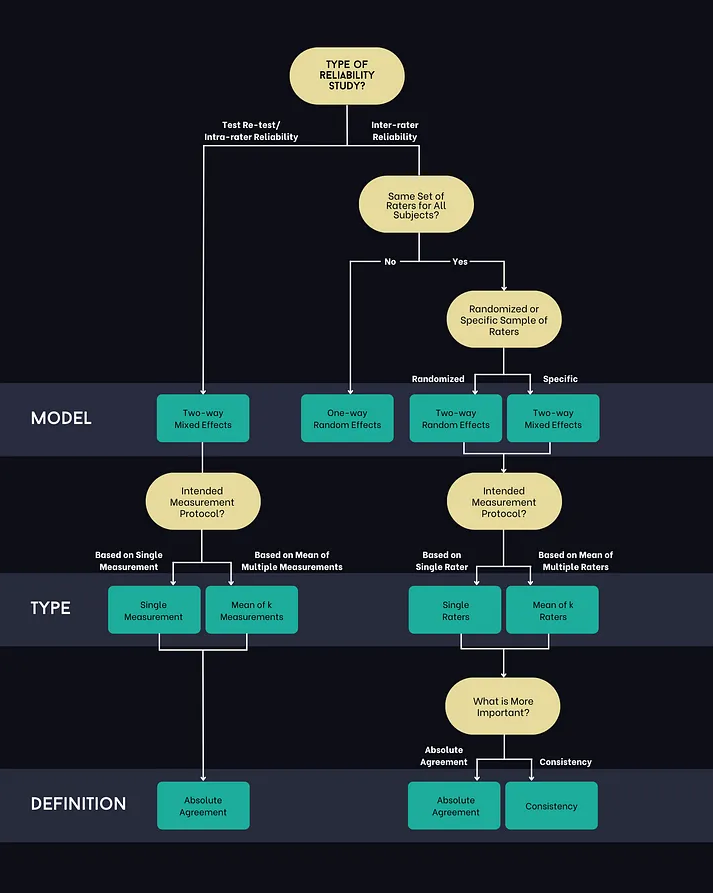
위 그림은 ICC 유형을 선택하는 의사결정 흐름도를 시각적으로 잘 정리한 자료이다. ICC는 McGraw & Wong이 제안한 모델을 기준으로 총 10가지 유형이 존재한다. 각각의 선택은 연구 설계에 따라 달라지며, 다음과 같은 과정을 거치면 적절한 유형을 결정할 수 있다.
첫 번째로, 연구 유형이 Test-Retest / Intra-rater Reliability인지, Inter-rater Reliability인지 알아본다. 만일 Test-Retest / Intra-rater Reliability라면, 같은 평가자가 같은 대상을 반복 측정하는 경우이기 때문에 Two-way Mixed Effects 모델을 사용한다. 반면에 Inter-rater Reliability라면 여러 평가자가 각 대상을 평가하는 경우이기 때문에, 다음 과정으로 넘어간다.
연구 유형이 Inter-rater Reliability일 때 모든 피평가자가 같은 평가자에게 평가되지 않았다면, 일부 평가자만 일부 피평가자를 평가하므로 One-way Random Effects 모델을 사용한다. 만일 모든 피평가자가 같은 평가자에게 평가되었다면, 평가자가 무작위 집단이라면 Two-way Random Effects 모델을 사용하고, 특정 평가자에 한정된다면 Two-way Mixed Effects 모델을 사용한다. 위 과정을 통해 ICC의 모델 중 어떤 것을 사용할 지 선택할 수 있다.
두 번째로 측정 프로토콜이 어떤 지 확인한다. 만일 한 번만 측정한다면 single rater/measurment을 사용하고, 여러 번 측정 후 평균을 사용한다면 multiple rater/measurment을 사용한다.
마지막으로 연구에서 중요한 것이 절대적 일치인지, 경향성 일치인지 판단한다. 진단 일치나 채점 점수 등 수치 자체가 같아야 하는 경우라면 Absolute Agreement를 사용하고, 순위 유지가 중요한 경우라면 Consistency를 사용하면 된다.
대중적으로 사용되는 ICC 방식
연구 현장에서 많이 쓰이는 ICC는 다음과 같다.
- ICC(2,1): Two-way random effects, single rater/measurment, absolute agreement
- ICC(2,k): Two-way random effects, multiple rater/measurment, absolute agreement
Two-way random effects 모델은 평가자와 피평가자 모두 무작위 샘플링된 것으로 간주한다. 따라서 평가자도 연구의 일반적인 모집단에서 랜덤하게 선택된 경우를 반영할 수 있어 일반화 가능성이 높다.
Absolute agreement는 단순히 측정값 간의 일관성만이 아니라, 측정값 자체가 정확히 일치하는지를 따진다. 이는 consistency보다 더 보수적이고 엄격한 방식이다. 또한 consistency는 평가자의 bias를 왜곡하는 반면, Absolute agreement는 systematic bias까지 감지할 수 있다.
따라서 Two-way random effects, Absolute agreement를 사용하는 ICC(2,1), ICC(2,k)를 실제 연구에서 많이 사용한다.
모던 ICC
초기 ICC는 ANOVA(분산 분석) 기반의 접근 방식으로 시작되었으나, 이후 랜덤 효과 모형(Random Effects Model)을 통해 발전하였다.
랜덤 효과 모형에서의 ICC
모던 ICC는 다음과 같은 one-way random effects 모형에서 정의된다. \[ Y_{ij} = \mu + \alpha_j + \varepsilon_{ij} \]
- \(Y_{ij}\)는 \(j\)번째 그룹의 \(i\)번째 측정값
- \(\mu\)는 모집단 전체의 평균
- \(\alpha_j\)는 그룹 \(j\)에 해당하는 랜덤효과
- \(\varepsilon_{ij}\)는 오차항
모던 ICC의 공식
모던 ICC는 다음과 같이 정의된다. \[ ICC = \frac{\sigma^2_{\alpha}}{\sigma^2_{\alpha} + \sigma^2_{\varepsilon}} \]
분자\((\sigma^2_{\alpha})\)는 그룹간 분산을 의미하고, 분모\((\sigma^2_{\alpha}+\sigma^2_{\varepsilon})\)은 전체 분산을 의미한다.
즉 ICC는 전체 변동에서 그룹간 변동이 차지하는 비율이 된다. 따라서 ICC값이 클 수록 같은 그룹 내에서 값들이 더 유사하다는 것을 알 수 있다.
증명
\(Y_{ij} = \mu + \alpha_j + \varepsilon_{ij}\)에서 \(\alpha_i \sim N(0, \sigma^2_{\alpha})\), \(\epsilon_{ij} \sim N(0, \sigma^2_{\varepsilon})\)이고 \(\alpha_i\)와 \(\varepsilon_{ij}\)은 서로 독립이다.
\(Var(Y_{ij}) = \sigma^2_{\varepsilon} + \sigma^2_{\alpha^2}\)
\[\begin{align} Cov(Y_{ij}, Y_{ik}) &= Cov(\mu + \alpha_{i} + \varepsilon_{ij}, \mu + \alpha_{i} + \varepsilon_{ik})\\ &= Cov(\alpha_i + \varepsilon_{ij},\alpha_i + \varepsilon_{ik}) \\ &= Cov(\alpha_i , \alpha_i) + Cov(\alpha_i, \varepsilon_{ik}) + Cov(\varepsilon_{ij}, \alpha_i) + Cov(\varepsilon_{ij}, \varepsilon_{ik}) \\ &= Var(\alpha_i) = \sigma^2_\alpha \end{align}\]모던 ICC의 장점
- 항상 0 이상이다
- 초기 ICC는 표본에서 음수값이 나올 수 있었음
- ANOVA와 결합 가능하다 \(\rightarrow\) 샘플 개수가 달라도 적용 가능하다
- 초기 ICC는 같은 크기의 그룹을 가정함
- 하지만 ANOVA 기반 ICC는 데이터 개수가 달라도 계산 가능
- 공변량을 포함할 수 있다
- 공변량을 통제한 후에도 같은 그룹 내에서 얼마나 유사한지 평가할 수 있음
- 복잡한 데이터 설계에 유리하다
모던 ICC의 한계점
- 샘플 ICC가 실제 모집단 ICC보다 클 가능성이 높다
- 초기 ICC는 편향되지 않은 추정량임
- 모던 ICC는 항상 0 이상이므로, 모집단의 ICC가 정확히 0일 때에도 샘플에서 ICC가 0보다 크게 나올 가능성이 있음
- 즉, 양의 편향을 가짐
- 여러 종류의 ICC가 존재\(\rightarrow\)어떤 ICC를 사용할지 논란이 된다
- 연구자마다 다른 ICC 통계량을 사용하며, 각 방법이 서로 다른 결과를 낼 수 있음
- 특정 연구 목적에 적합한 ICC를 신중하게 선택해야 함
ICC R 실습
특정 ICC 방법을 실행하는 R코드
library(irr)
ratings <- data.frame(
Rater1 = c(4, 5, 3, 4, 2),
Rater2 = c(5, 5, 4, 4, 3),
Rater3 = c(4, 5, 3, 5, 2)
)
result <- icc(ratings, model = "twoway", type = "agreement", unit = "single")
print(result)출력
Single Score Intraclass Correlation
Model: twoway
Type : agreement
Subjects = 5
Raters = 3
ICC(A,1) = 0.792
F-Test, H0: r0 = 0 ; H1: r0 > 0
F(4,9.09) = 15.1 , p = 0.000482
95%-Confidence Interval for ICC Population Values:
0.375 < ICC < 0.973Shrout & Fleiss의 6개 방법을 모두 보여주는 R코드
library(psych)
ICC(ratings)출력
Call: ICC(x = ratings)
Intraclass correlation coefficients
type ICC F df1 df2 p lower bound upper bound
Single_raters_absolute ICC1 0.79 12 4 10 0.00072 0.37 0.97
Single_random_raters ICC2 0.79 15 4 8 0.00085 0.37 0.97
Single_fixed_raters ICC3 0.82 15 4 8 0.00085 0.40 0.98
Average_raters_absolute ICC1k 0.92 12 4 10 0.00072 0.64 0.99
Average_random_raters ICC2k 0.92 15 4 8 0.00085 0.64 0.99
Average_fixed_raters ICC3k 0.93 15 4 8 0.00085 0.66 0.99
Number of subjects = 5 Number of Judges = 3
See the help file for a discussion of the other 4 McGraw and Wong estimates,lmer 방식의 모던 ICC R코드
df <- data.frame(
subject = rep(1:5, each = 3),
rater = rep(1:3, times = 5),
score = c(80, 82, 81,
75, 76, 74,
90, 89, 91,
70, 72, 71,
85, 86, 84)
)
library(lme4)
library(performance)
model <- lmer(score ~ 1 + (1 | subject) + (1 | rater), data = df)
icc(model)출력
# Intraclass Correlation Coefficient
Adjusted ICC: 0.985
Unadjusted ICC: 0.985모던 ICC에서 CI 구하기
lmer을 이용한 모던 ICC에서는 CI를 직접 제공하지 않는 것을 알 수 있다. 이는 ICC는 비선형 함수이고, \(\sigma^2\)자체는 정규분포를 따르지 않기 때문에 정규 근사(CI ≈ estimate ± 1.96 × SE)가 잘 맞지 않기 때문이다.
그러나 bootstrapping 방식을 통해서 충분히 CI를 추정할 수 있다. bootstrap은 데이터를 반복적으로 다시 샘플링해서, 어떤 통계량의 표본 분포를 직접 만들어내는 기법이다. 원래 데이터를 기준으로 같은 크기의 샘플을 복원추출로 다시 만든 후, 새롭게 만들어진 데이터로 lmer을 적합한다. 그 모델에서 ICC를 계산하고, 이 과정을 계속 반복하여 ICC의 분포를 만든다. 그 값들의 분포에서 CI을 추출할 수 있다.
아래는 그 과정을 실행하는 코드이다.
library(lme4)
library(performance)
set.seed(123)
n_subjects <- 30
n_raters <- 6
ratings_per_subject <- 3
subjects <- 1:n_subjects
raters <- 1:n_raters
# 데이터프레임 생성
df <- do.call(rbind, lapply(subjects, function(s) {
r <- sample(raters, ratings_per_subject)
mu <- rnorm(1, mean = 75, sd = 5) # subject 고유의 평균 실력
data.frame(
subject = factor(s),
rater = factor(r),
score = rnorm(ratings_per_subject, mean = mu, sd = 2)
)
}))
model <- lmer(score ~ 1 + (1 | subject) + (1 | rater), data = df, REML = TRUE)
performance::icc(model, ci =TRUE, iterations = 1000)출력
# Intraclass Correlation Coefficient
Adjusted ICC: 0.794 [0.472, 0.934]
Unadjusted ICC: 0.794 [0.472, 0.934]Citation
@online{choi2025,
author = {Choi, Sungho},
title = {Intraclass {Correlation} {Coefficient} {공부하기}},
date = {2025-03-24},
url = {https://blog.zarathu.com/posts/2025-03-24-IntraclassCorrelationCoefficient/},
langid = {en}
}