지연 효과와 비선형 관계를 모두 고려한 모델인 DLNM의 확장 버전, the Extended DLNM에 대해 소개하고, R의 dlnm 패키지를 이용하여 the Extended DLNM을 적합시키는 방법에 대해 소개합니다.
1. DLNM이란?
어떤 노출 요인(exposure, \(X\))은 관측 당시 뿐만 아니라, 일정 시간이 지난 후 그 효과가 발생할 수 있습니다. 즉, ‘지연 효과’를 가집니다. 모형에 지연 효과를 포함한다면 더 효과적인 예측을 진행할 수 있으며, 이를 위해 시차에 대한 차원이 추가적으로 필요합니다.
지연 효과를 고려한 모델로 DLM(Distributed Lag Models)가 존재합니다. 하지만 DLM은 선형적 효과를 다루는데 더 적합하므로, 비선형적 효과를 표현하는데 한계가 있습니다. DLNM은 DLM과 달리 비선형적 효과를 반영한, 더 flexible한 모형입니다.
DLNM은 cross-basis(교차 기저)를 정의하여 \(X\)(exposure)와 그것의 시차(lag)에 따른 \(Y\)(response)의 관계를 고려함으로써 지연 효과까지 반영합니다. 즉, cross-basis란 exposure-lag-response의 관계를 3차원 상의 공간에서 표현한 것입니다. cross-basis를 정의하기 위해 exposure-response 차원과 lag-response 차원에서 사용할 basis function(기저 함수)을 선택해야 하는데, 어떤 basis function을 선택하느냐에 따라 선형적/비선형적 관계를 고려할지 결정할 수 있습니다.
2. the Extended DLNM이란?
DLNM과 the Extended DLNM의 주요 차이점은 matrix of exposure histories의 정의입니다. matrix of exposure histories는 \(n\)개의 관측치 각각에 대한 lag \(\ell\)에서의 exposure 값들로 이루어진 행렬입니다. 즉, exposure 값들로 이루어진 \(n \times (L - \ell_0 + 1)\) 크기의 행렬을 말합니다. 이 matrix of exposure histories는 study design과 수집된 정보에 따라 다르게 구성됩니다.
DLNM을 사용하는 일반적인 시계열 데이터에서 matrix of exposure histories의 \([t, \ell]\) 값은 \([t+1, \ell+1]\) 값과 동일합니다. \(n\)개의 관측치가 하나의 변수에 대한 여러 시점의 관측값이기 때문입니다.
예를 들어, 다음과 같은 데이터를 살펴봅시다. 아래 시계열 데이터는 1987-01-01부터 1987-01-15까지의 미세먼지(pm10)를 기록한 것입니다.
This is dlnm 2.4.7. For details: help(dlnm) and vignette('dlnmOverview').
R의 dlnm 패키지를 이용하여 the Extended DLNM을 적합시키는 방법에 대해 소개하겠습니다. 사실, 함수의 input으로 시계열 데이터 대신 matrix of exposure histories를 입력한다는 부분을 제외하면 기본 DLNM을 적합시키는 방법과 크게 다르지 않습니다.
the Extended DLNM의 R 실습에서 사용될 데이터는 dlnm 패키지에 포함되어 있는 drug와 nested 데이터셋입니다.
drug 데이터는 환자별 시간에 따른 약물 복용량의 효과에 대한 데이터입니다. 해당 실험은 200명의 무작위 추출된 환자들에 대해 진행되었으며, 각 환자들은 4주 중 무작위로 선정된 2주동안 투약을 받게 되고, 약물 복용량은 매주 달라집니다. 아래 데이터를 보면, 각 환자별로 주별 복용량(day1.7, day8.14, day15.21, day22.28)이 기록되어 있으며, out에 28일째에 측정된 outcome 값이 기록되어 있습니다.
id out sex day1.7 day8.14 day15.21 day22.28
1 1 46 M 0 0 40 37
2 2 50 F 0 47 55 0
3 3 7 F 56 22 0 0
4 4 70 M 91 0 0 87
5 5 -3 F 0 42 28 0
nested 데이터는 시간에 따른 노출 요인(exposure)과 암 사이의 연관성에 대한 nested case-control study 데이터입니다. 300명의 case 집단과 300명의 control 집단에 대한 데이터가 포함되어 있습니다. 아래 데이터의 case에 case(1)/control(0) 여부가 기록되어 있으며, exp15-exp60은 15세부터 65세까지 5년 간격으로 평균 노출 요인(exposure)을 구한 값입니다. 만약, 환자의 나이(age)가 컬럼에 해당하는 나이보다 적다면 해당 컬럼에는 NA가 입력됩니다. 예를 들어, 아래 데이터의 4번 환자는 52세이기 때문에 exp55 이후의 컬럼에는 NA가 입력되어 있습니다.
DLNM을 적합시키기 전, 데이터의 형태를 matrix of exposure histories 형태로 바꿔주어야 합니다.
drug 데이터의 matrix of exposure histories에서 lag0에 해당하는 값은 28일째의 약물 복용량입니다. 즉, lag0-lag6은 마지막 주의 약물 복용량, lag7-lag13은 셋째 주의 약물 복용량입니다. drug 데이터의 주별 약물 복용량 값을 7번씩 반복하여 다음과 같은 matrix of exposure histories를 만들어줍니다.
nested 데이터의 matrix of exposure histories에서 lag0에 해당하는 시점은 환자의 나이마다 다릅니다. 예를 들어, 52세 환자의 lag0 시점은 52년의 값이고, 65세 환자의 lag0 시점은 65년의 값입니다. 이런 경우, matrix of exposure histories를 만들기 까다로운데, dlnm 패키지에서는 이런 경우의 matrix of exposure histories를 만들어주는 exphist()라는 함수를 제공합니다. exphist() 함수는 다음과 같이 이용합니다.
exphist(exp, times, lag, fill=0)
exp에는 exposure profile(관측 첫 시점부터 매 시점의 exposure 값)을 입력합니다. times에는 lag0에 해당하는 시점을 입력합니다. times에 입력된 시점부터 시점을 거슬러가며 각 시차별 exposure 값이 구해집니다. lag에는 maximum lag 또는 lag range를 입력합니다. fill에는 어떤 시차에 해당하는 exposure 값이 존재하지 않을 때 채울 값을 입력합니다.
exphist() 함수를 이용하여 다음과 같은 matrix of exposure histories를 만들어줍니다. nested 데이터의 평균 노출 요인 값에 0, 0, 0을 추가하고 각 데이터를 5번씩 반복하여 1년부터 65년까지에 해당하는 exposure profile을 만들고 이 값을 exp에 넣습니다. times에는 각 환자별 나이(age)를 넣습니다. nested 데이터를 이용한 분석에서는 lag3부터 lag40까지의 데이터만 사용할 예정이기 때문에 lag에는 다음과 같이 lag range를 벡터로 넣어줍니다. nested 데이터의 matrix of exposure histories는 다음과 같습니다.
drug 데이터와 dlnm 패키지의 함수를 이용하여 약물 복용량과 outcome 사이의 관계에 대해 분석해보고자 합니다.
먼저, 약물 복용량에 대한 cross-basis matrix를 만들어야 합니다. crossbasis() 함수를 이용합니다. crossbasis()의 첫 번째 인수에는 matrix of exposure histories를 넣어줍니다. lag에는 lag-response 차원에서 시차를 얼마나 고려할지 lag period를 입력합니다. maximum lag 또는 lag range를 입력해야하며, minimum lag는 기본값이 0으로 지정되어 있습니다. 이때, lag period는 matrix of exposure histories의 시차 범위와 일치해야 합니다. argvar에는 exposure-response 차원에서 사용할 basis function, arglag에는 lag-response 차원에서 사용할 basis function을 입력합니다.
drug 데이터의 cross-basis는, exposure-response 차원에서 simple linear function을 이용하고, lag-response 차원에서 natural cubic spline을 이용합니다. 이 때, natural cubic spline에서 lag9, 18을 knots로 이용하는데, 이는 lag9, 18을 기준으로 구간을 나눠 각 구간에서 cubic regression model을 적합시킨다는 의미입니다.
summary() 함수를 통해 cross-basis matrix의 세부 사항을 확인할 수 있습니다.
CROSSBASIS FUNCTIONS
observations: 200
range: 0 to 100
lag period: 0 27
total df: 4
BASIS FOR VAR:
fun: lin
intercept: FALSE
BASIS FOR LAG:
fun: ns
knots: 9 18
intercept: TRUE
Boundary.knots: 0 27
위에서 생성된 cross-basis 객체인 cbdrug를 회귀식에 포함시키고, 성별에 대한 효과를 보정하여 단순 선형 회귀 분석을 진행합니다. 모형을 통해 추정된 약물 복용량 및 그 시차에 대한 효과를 crosspred() 함수를 통해 확인할 수 있습니다. crosspred()의 첫 번째 인수에는 cross-basis 객체를, 두 번째 인수에는 cross-basis 객체를 사용한 모델을 입력합니다. 다음 코드에서, crosspred()의 at은 약물 복용량이 0:20*5(즉, 0, 5, 10, 15, …, 100)일 때의 outcome을 예측하라는 뜻입니다.
위 코드는 약물 복용량이 50일때의 overall cumulative effects 추정치(allfit)와 95% 신뢰구간(alllow, allhigh) 추출한 것입니다. 이때, overall cumulative effects는 lag period인 28일동안 약물 복용량이 50으로 유지되었을 때 outcome의 전체적인 증가량 또는 약물 복용량 50이 28일 뒤 미치는 총 영향으로 해석될 수 있습니다.
위에서처럼 all-로 시작하는 객체들을 통해서는 전반적인 추정값을 확인할 수 있고, mat-으로 시작하는 객체들을 통해서는 특정 약물 복용량과 시차의 조합에 따른 추정 결과를 확인할 수 있습니다. 다음 코드는 lag3에서의 약물 복용량이 20일 때, outcome의 증가량을 추출한 것입니다. ?crosspred를 통해 crosspred()의 더 많은 기능을 확인할 수 있습니다.
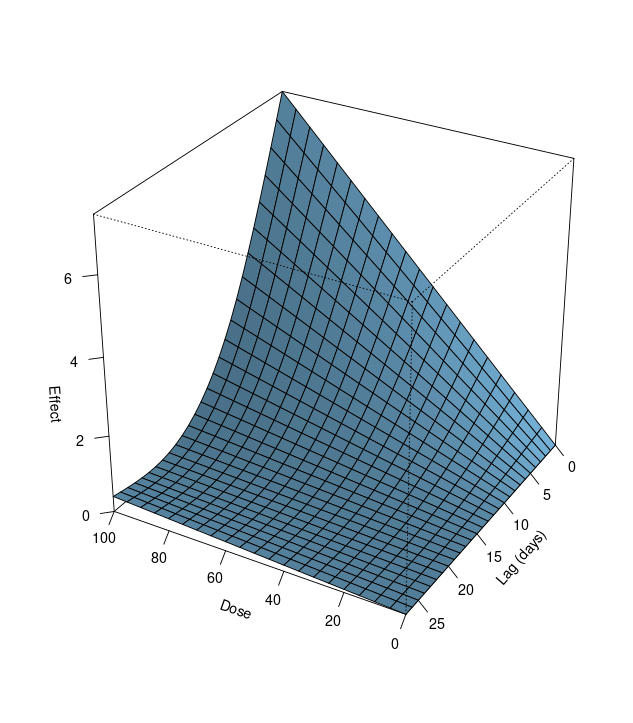
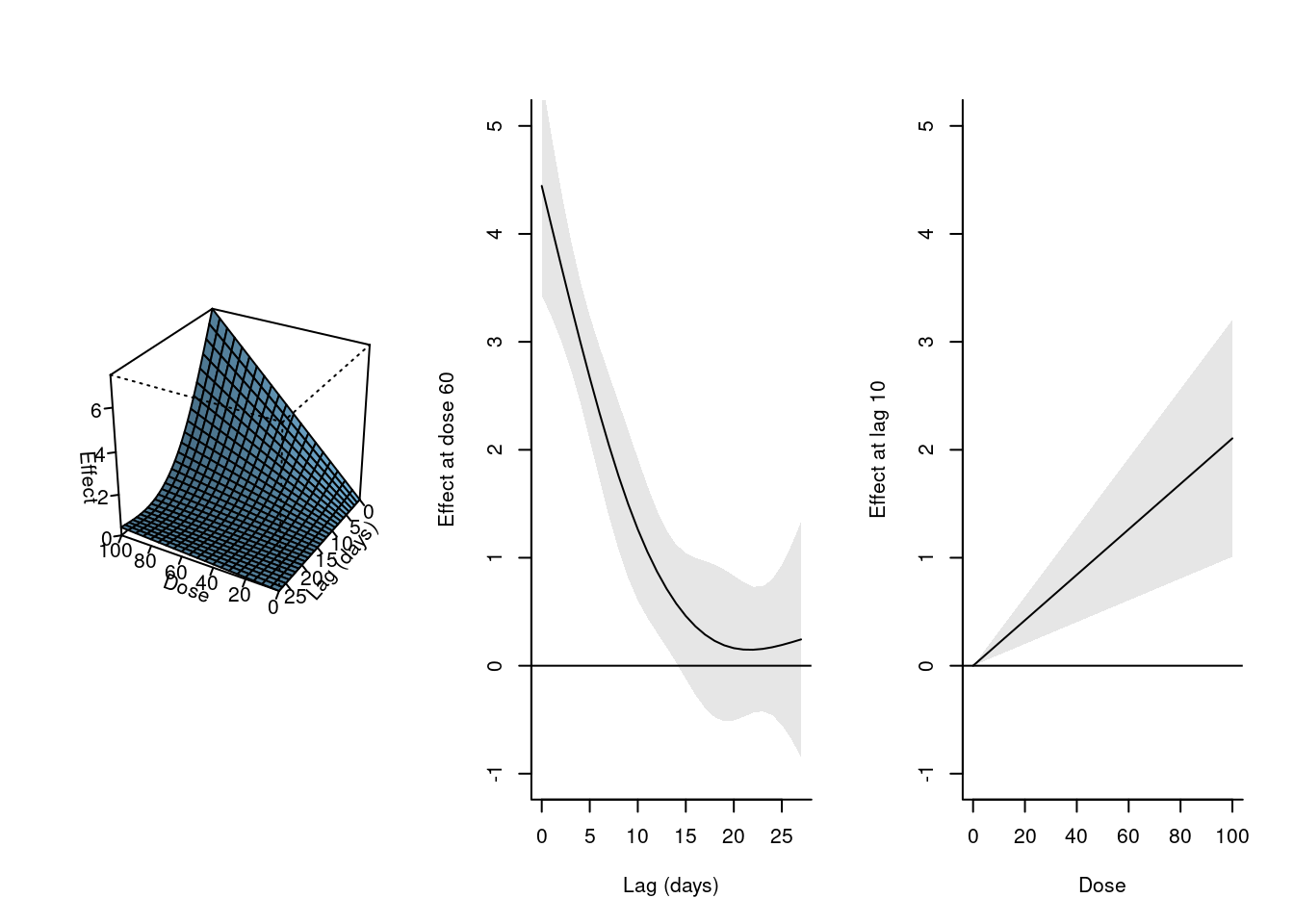
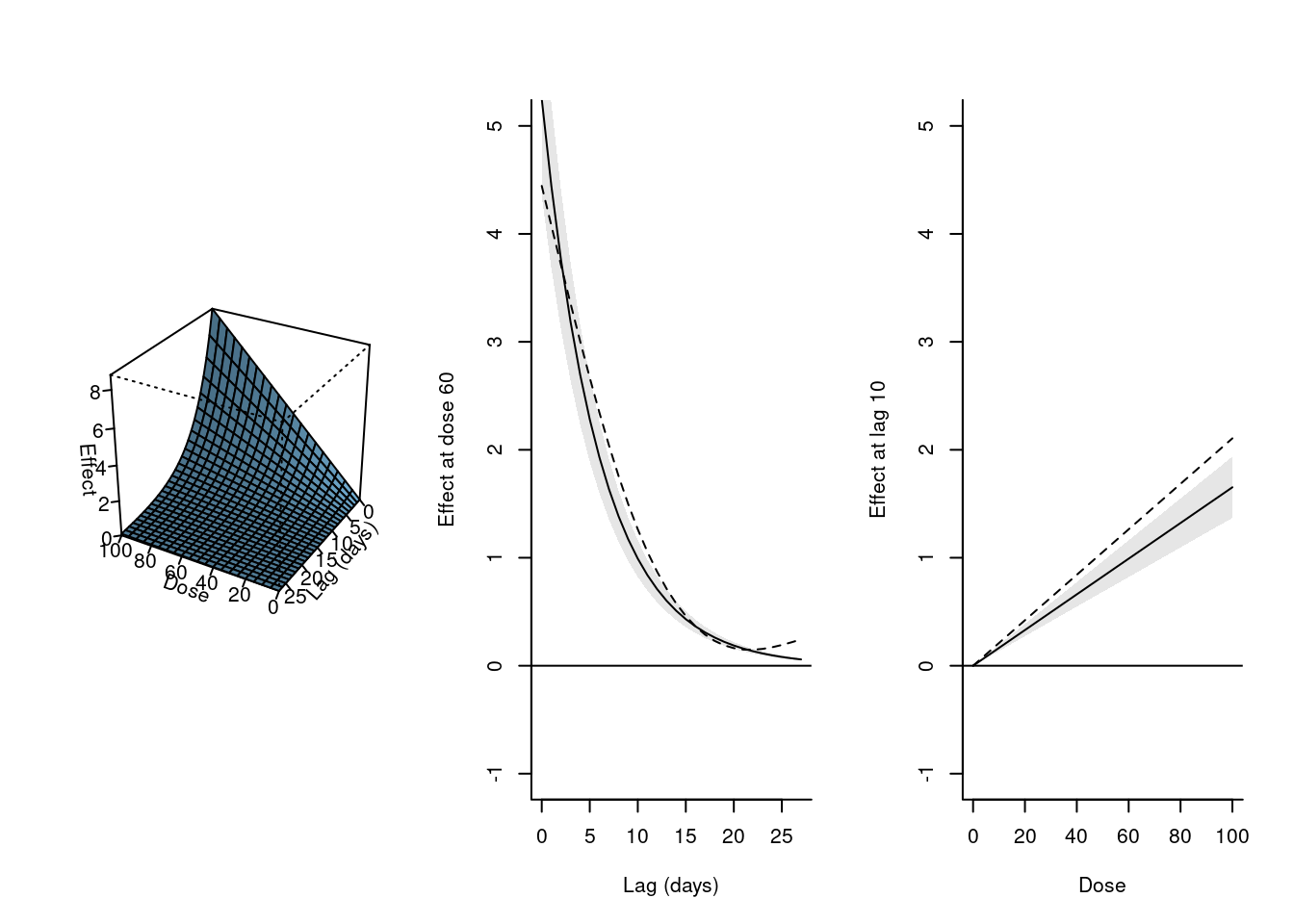
par(mfrow=c(1,3))plot(pdrug, zlab="Effect", xlab="Dose", ylab="Lag (days)")plot(pdrug, var=60, ylab="Effect at dose 60", xlab="Lag (days)", ylim=c(-1,5))plot(pdrug, lag=10, ylab="Effect at lag 10", xlab="Dose", ylim=c(-1,5))
첫 번째 그래프는 회귀 모델을 통해 추정한 exposure-lag-response 관계를 3차원 공간에 그려놓은 것입니다. 약물 복용량과 시차의 변화에 따라 effect가 어떻게 달라지는지 확인할 수 있습니다. 그래프에 따르면 약물 복용량의 효과는 복용 후 첫 번째 날에 나타나고 15-20일 후에 사라지는 경향이 있음을 알 수 있습니다.
두 번째와 세 번째 그래프는 약물 복용량이 60일 때의 lag-response curve와 lag가 10일 때 exposure-response curve를 그린 것입니다. 각각 var=60, lag=10을 지정하여 3차원상의 첫 번째 그래프의 단면을 자른 것과 같습니다. cross-basis matrix를 만들 때 basis function을 지정했던대로, lag-response 차원에서는 natural cubic spline, exposure-response 차원에서는 simple linear function 형태로 나타나는 것을 확인할 수 있습니다.
3.3 A more complex DLNM
neseted 데이터와 dlnm 패키지의 함수를 이용하여 노출 요인(exposure)에 대한 장기간의 노출이 암에 어떤 영향을 미치는지 분석하고자 합니다.
최근 3년(lag0-2)간의 노출은 암에 영향을 주지 않는다고 가정해봅시다. 따라서 matrix of exposure histories에는 lag3부터의 데이터만 있으면 됩니다.
먼저, cross-basis matrix를 만듭니다. crossbasis() 함수를 이용합니다. lag3부터 lag40까지의 데이터만 이용할 것이므로, lag에 c(3,40)을 넣어줍니다. exposure-response 차원에서는 basis 함수로 quadratic spline을 사용하고, exposure-lag 차원에서는 natural cubic spline을 사용합니다. quadratic spline의 자유도(df)와 차수(degree)를 입력해야하며, single knot는 별도로 지정하지 않으면 중앙값으로 지정됩니다. natural cubic spline은 intercept=F를 입력하여 intercept를 제외합니다. 위에서 lag0-2는 고려하지 않는다고 하였으므로, intercept를 제외함으로써 위 가정과 일치하게 시차 차원에서의 null effect를 예측할 수 있습니다.
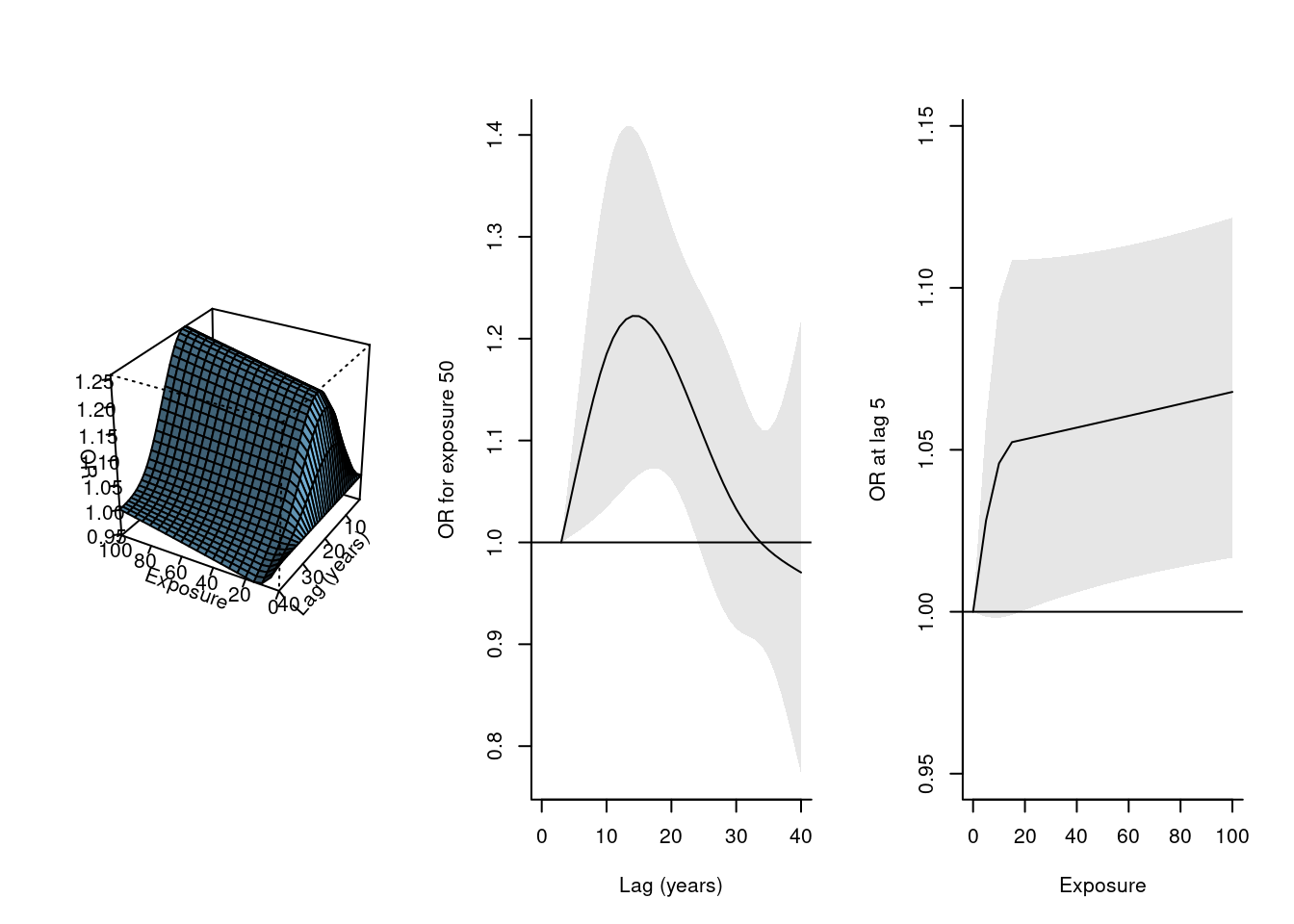
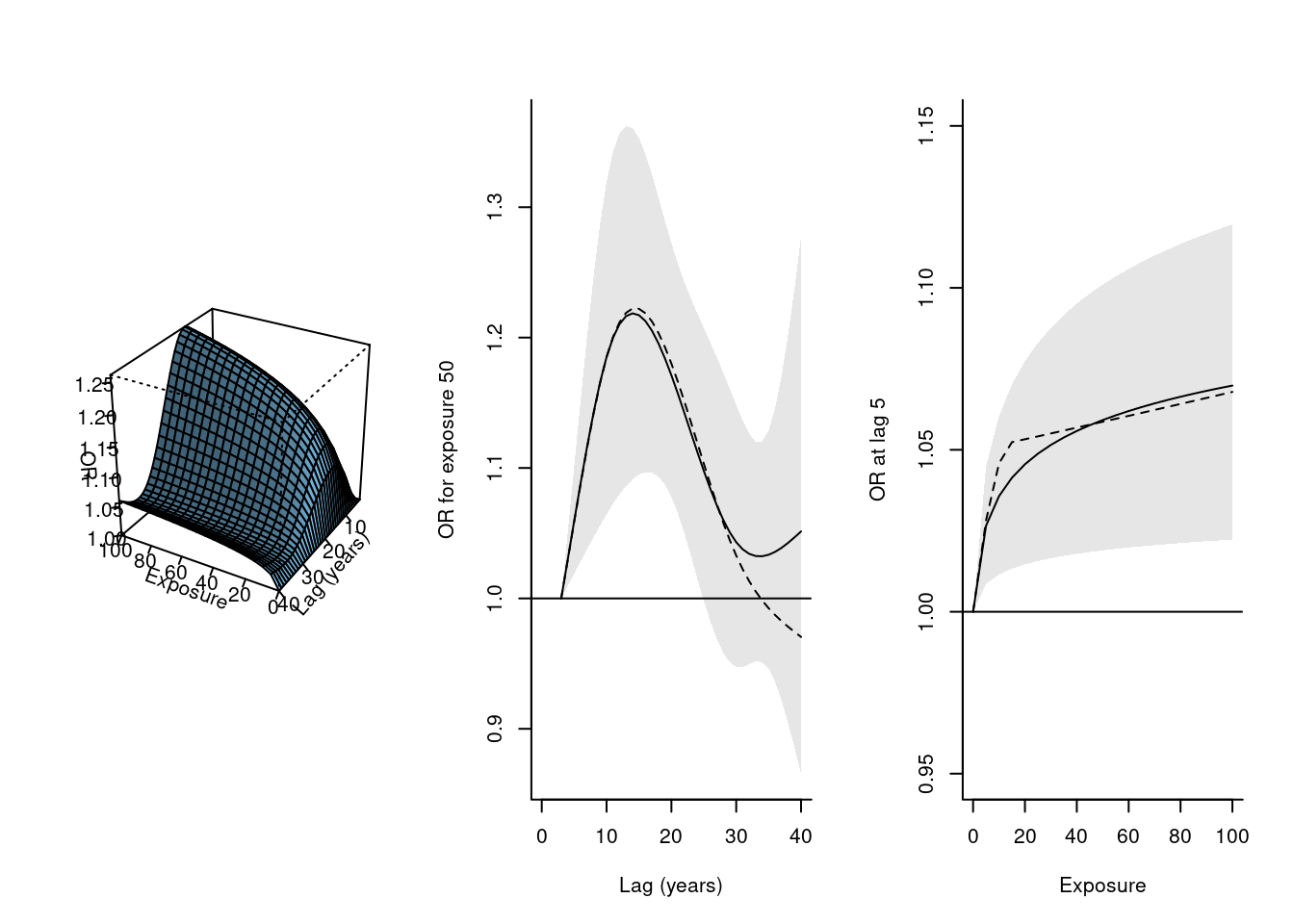
par(mfrow=c(1,3))plot(pnest, zlab="OR", xlab="Exposure", ylab="Lag (years)")plot(pnest, var=50, ylab="OR for exposure 50", xlab="Lag (years)", xlim=c(0,40))plot(pnest, lag=5, ylab="OR at lag 5", xlab="Exposure", ylim=c(0.95,1.15))
첫 번째 그래프는 노출 요인과 암 사이의 exposure-lag-response 관계를 3차원 상에서 시각화한 것입니다. 그래프에 따르면 노출 초기엔 암의 위험성을 증가시키다가 점차 감소한다는 사실을 확인할 수 있습니다.
두 번째와 세 번째 그래프는 exposure이 50일 때의 lag-response curve와 lag가 5일 때 exposure-response curve를 그린 것입니다. 두 번째 그래프를 통해 노출 후 10-15년이 지났을 때 암의 위험성이 가장 크게 증가하며, 30년이 지났을 때쯤부턴 거의 원 상태로 되돌아온다는 사실을 확인할 수 있습니다. 세 번째 그림을 통해 노출 요인의 양이 20으로 증가할 때까지는 위험성이 크게 증가하지만 그 이후로는 위험성이 천천히 증가함을 확인할 수 있습니다.
3.4 Extended prediction summaries
crosspred()의 at과 lag 인자를 통해 특정 exposure 값 또는 lag에서의 effect summaries를 얻을 수 있습니다. 이때, nested 데이터의 matrix of exposure histories를 만들 때 사용한 함수인 exphist()를 사용한다면, 특정 exposure history에서의 effect summaries를 얻을 수 있습니다.
예를 들어, ’3.3 A more complex DLNM’에서 이용한 nested 데이터를 다시 분석해봅시다. 5년 동안의 exposure 값이 10이고, 그 이후 5년 간은 0, 그 이후 10년간은 13일 때의 effect summary를 구하고자 할 때, 아래와 같이 exposure history를 만들 수 있습니다.
위의 코드를 통해 해당 exposure history에서의 OR 추정치는 3.5임을 알 수 있습니다.
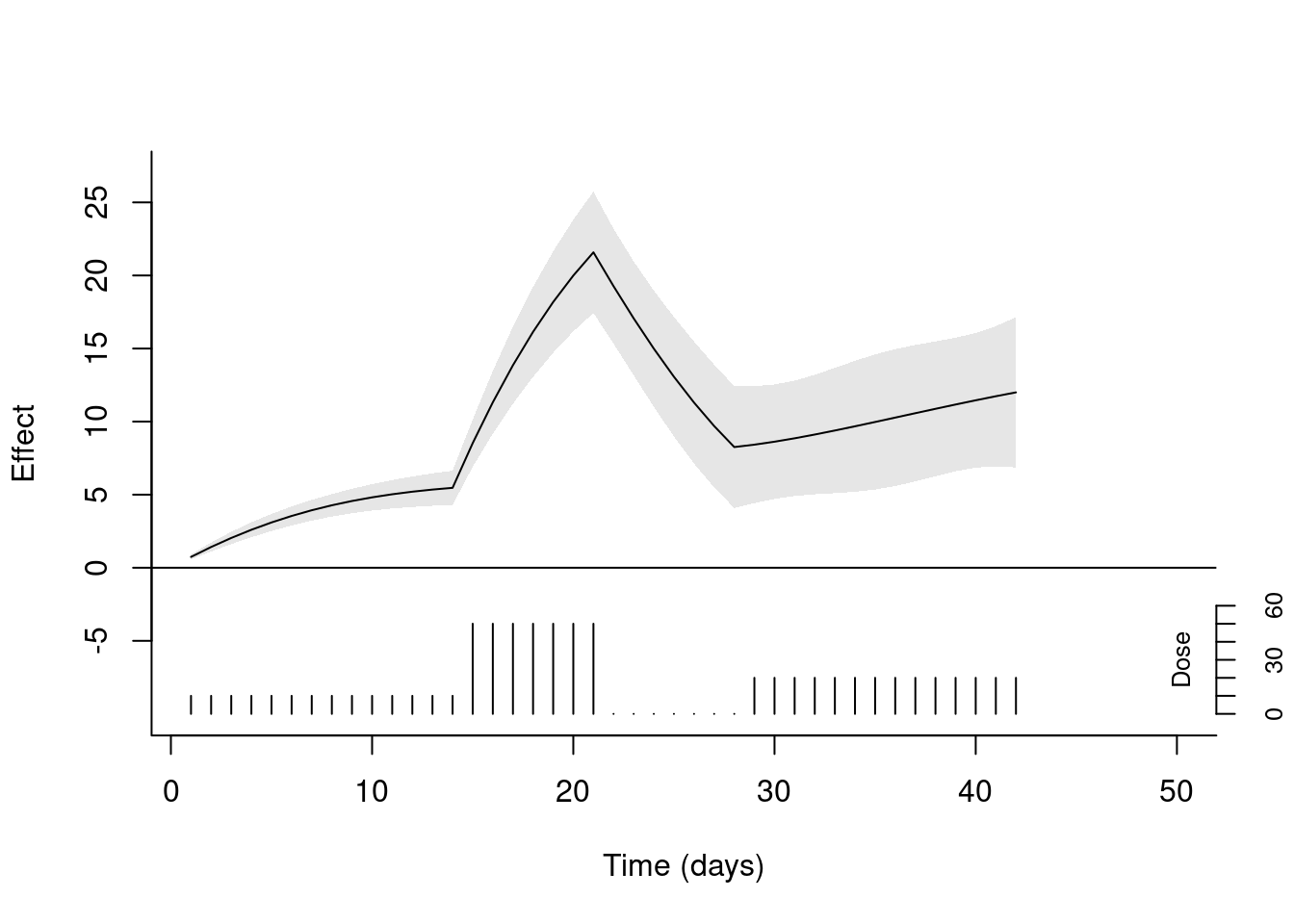
이 방법을 통해 여러 개의 time-varying exposure histories를 만들어 effect summaries를 구할 수 있습니다. ’3.2 A simple DLM’에서 이용한 drug 데이터를 다시 분석해봅시다. 환자의 2주 동안의 약물 복용량이 10이고, 그 후 1주간은 50이고, 그 후 1주간은 복용하지 않았을 때, 각 시점에서의 effect summary를 구해봅시다. 아래와 같이 각 시점에서의 exposure history을 만들어줍니다.
cross-basis 객체를 생성할 때, exposure와 lag 차원에서 사용할 basis function을 사용자 정의 함수로 지정할 수 있습니다. 이때, 사용자 정의 함수의 첫 번째 인자는 반드시 \(X\)값이어야하고, return 값은 변환된 벡터 혹은 행렬이어야 합니다.
’3.3 A more complex DLNM’의 세 번째 plot을 보면, exposure-response 차원에서의 quadratic spline은 log 함수와 비슷한 형태임을 알 수 있습니다. cross-basis 객체를 생성할 때, exposure-response 차원에서의 basis function을 quadratic spline이 아닌 log 함수를 이용해봅시다.
CROSSBASIS FUNCTIONS
observations: 200
range: 0 to 100
lag period: 0 27
total df: 1
BASIS FOR VAR:
fun: lin
intercept: FALSE
BASIS FOR LAG:
fun: fdecay
scale: 6
mdrug2<-lm(out~cbdrug2+sex, drug)pdrug2<-crosspred(cbdrug2, mdrug2, at=0:20*5)par(mfrow=c(1,3))plot(pdrug2, zlab="Effect", xlab="Dose", ylab="Lag (days)")plot(pdrug2, var=60, ylab="Effect at dose 60", xlab="Lag (days)", ylim=c(-1,5))lines(pdrug, var=60, lty=2)plot(pdrug2, lag=10, ylab="Effect at lag 10", xlab="Dose", ylim=c(-1,5))lines(pdrug, lag=10, lty=2)
점선은 3.2에서 추정한 결과를 나타낸 것입니다. lag-response 차원에서 basis function으로 exponential decay 함수를 사용했을 때와 natural cubic spline을 사용했을 때의 결과가 유사함을 확인할 수 있습니다.
References
Gasparrini A, Armstrong B, Kenward MG. Distributed lag non-linear models. Stat Med. 2010 Sep 20;29(21):2224-34. doi: 10.1002/sim.3940. PMID: 20812303; PMCID: PMC2998707.